
About
If you are in search of Data Science interview questions, then this is the right place for you to alight. Preparing for an interview is definitely quite challenging and complicated. It is very problematic with respect to what data science interview questions you will be inquired about. Unquestionably, you have heard this saying a lot of times, that Data science is called the most hyped up job of the 21st century. The demand for data scientists has been growing drastically over the years due to the increased importance of big data.
Learn More
Data Science Interview Questions & Answers
Many predictions have been made for the role of a data scientist, and according to IBM’s predictions, the demand for this role will soar 28% by 2021. To give you the much of the time asked Data science interview questions, this article has been structured strikingly. We have segregated the most important interview questions based on their complexity and belonging. This article is the perfect guide for you as it contains all the questions you should expect; it will also help you to learn all the concepts required to pass a data science interview.

Q-1: What is Data Science, and why is it important?
The main section in this rundown is presumably one of the most fundamental ones. However, the majority of the interviewers never miss this question. To be very specific, data science is the study of data; a blend of machine learning theories or principles, different tools, algorithms are also involved in it. Data science also incorporates the development of different methods of recording, storing, and analyzing data to withdraw functional or practical information constructively. This brings us to the main goal of data science that is to use raw data to unearth concealed patterns.
Data Science is essential for improved marketing. To analyze their marketing strategies, companies make major use of data and thereby create better advertisements. By analyzing customers’ feedback or response, decisions can also be made.
Q-2: What is Linear Regression?
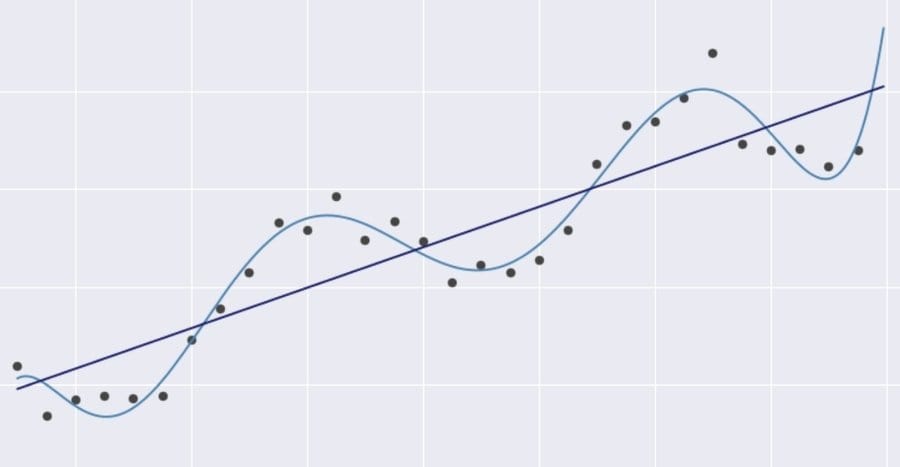
Linear Regression is a supervised learning algorithm where the score of a variable M is predicted statistically by using the score of a second variable N and thereby showing us the linear relationship between the independent and dependent variables. In this case, M is referred to as the criterion or dependent variable, and N is referred to as the predictor or independent variable.
The main purpose that linear regression serves in data science is to tell us how two variables are related to producing a certain outcome and how each of the variables has contributed to the final consequence. It does this by modeling and analyzing the relationships between the variables and therefore shows us how the dependent variable changes with respect to the independent variable.
Q-3: What are Interpolation and Extrapolation?
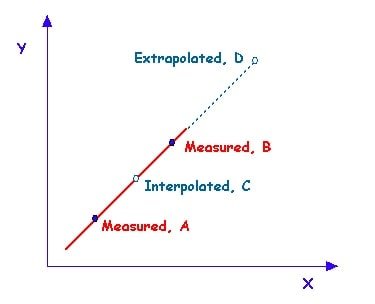
Let us move towards the next entry of Data Science interview questions. Well, interpolation is to approximate value from two values, which are chosen from a list of values, and extrapolating is estimating value by extending known facts or values beyond the scope of information that is already known.
So basically, the main difference between these two is that Interpolation is guessing data points that are in the range of the data that you already have. Extrapolation is guessing data points that are beyond the range of data set.
Q-4: What is a confusion matrix?
This is a very commonly asked data science interview question. To answer this question, your answer can be sentenced in this manner; that is, we use Confusion Matrix to estimate the enactment of a classification model, and this is done on a set of test data for which true values are known. This is a table that tabularizes the actual values and predicted values in a 2×2 matrix form.

- True Positive: This represents all the accounts where the actual values, as well as the predicted values, are true.
- True Negative: This represents all of those records where both the actual and predicted values are both false.
- False Positive: Here, the actual values are false, but the predicted values are true.
- False Negative: This represents all the records where the actual values are verifiable or true, and the predicted values are incorrect.
Q-5: What do you understand by a decision tree?
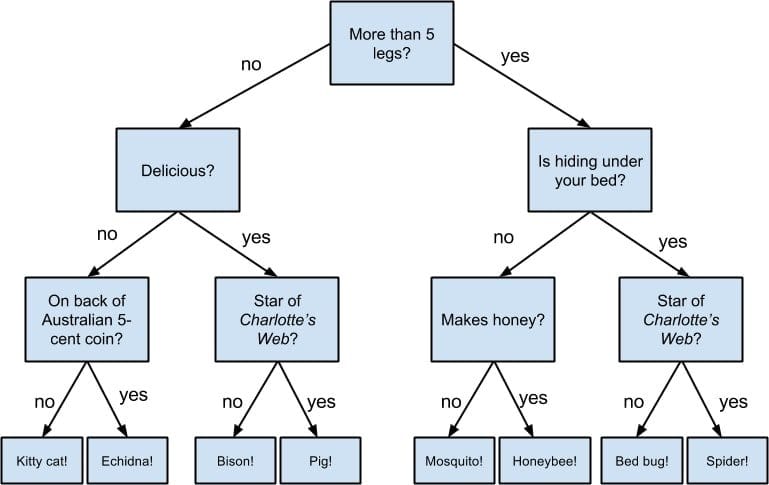
This is one of the top data science interview questions, and to answer this, having a general thought on this topic is very crucial. A decision tree is a supervised learning algorithm that uses a branching method to illustrate every possible outcome of a decision, and it can be used for both classification and regression models. Thereby, in this case, the dependent value can be both a numerical value and a categorical value.
There are three unique sorts of nodes. Here, each node denotes the test on an attribute, each edge node denotes the outcome of that attribute, and each leaf node holds the class label. For instance, we have a series of test conditions here, which gives the final decision according to the outcome.
Q-6: How is Data modeling different from Database design?
This could be the next important data science interview question, so you need to be prepared for this one. To demonstrate your knowledge of data modeling and database design, you need to know how to differentiate one from the other.
Now, in data modeling, data modeling techniques are applied in a very systematic manner. Usually, data modeling is considered to be the first step required to design a database. Based on the relationship between various data models, a conceptual model is created, and this involves moving in different stages, starting from the conceptual stage to the logical model to the physical schema.
Database design is the main process of designing a particular database by creating an output, which is nothing but a detailed logical data model of the database. But sometimes, this also includes physical design choices and storage parameters.
Q-7:What do you know about the term “Big Data”?
Do I even have to mention the importance of this particular interview question? This is probably the most hyped-up data analytics interview question and along with with with that a major one for your Big Data interview as well.
Big Data is a term that is associated with large and complex datasets, and therefore, it cannot be handled by a simple relational database. Hence, special tools and methods are required to handle such data and perform certain operations on them. Big data is a real life-changer for businessmen and companies as it allows them to understand their business better and take healthier business decisions from unstructured, raw data.
Q-8:How is Big Data analysis helpful in increasing business revenue?
A must-ask question for your Data scientist interview as well as your Big Data interviews. Nowadays, big data analytics are used by many companies, and this is helping them greatly in terms of earning additional revenue. Business companies can differentiate themselves from their competitors and other companies with the help of big data analysis, and this once again helps them to increase revenue.
The preferences and needs of customers are easily known with the help of big data analytics, and according to those preferences, new products are launched. Thus, by implementing this, it allows companies to encounter a significant rise in revenue by almost 5-20%.
Q-9: Will you optimize algorithms or code to make them run faster?
This is another most recent Data Science interview question that will likewise help you in your big data interview. The answer to this data science interview question should undoubtedly be a “Yes.” This is because no matter how efficient a model or data we use while doing a project, what matters is the real-world performance.
The interviewer wants to know whether you had any experience in optimizing code or algorithms. You do not have to be scared. To accomplish and impress the interviewers in the data science interview, you just have to be honest about your work.
Do not hesitate to tell them if you do not have any experience in optimizing any code in the past; only share your real experience, and you will be good to go. If you are a beginner, then the projects you have previously worked on will matter here, and if you are an experienced candidate, you can always share your involvement accordingly.
Q-10: What is A/B Testing?

A/B testing is a statistical hypothesis testing where it determines whether a new design brings improvement to a webpage, and it is also called “split testing.” As the name recommends, this is essentially a randomized investigation with two parameters A and B. This testing is also done to estimate population parameters based on sample statistics.
A comparison between two webpages can also be done with this method. This is done by taking many visitors and showing them two variants – A and B. the variant which gives a better conversion rate wins.
Q-11: What is the difference between variance and covariance?
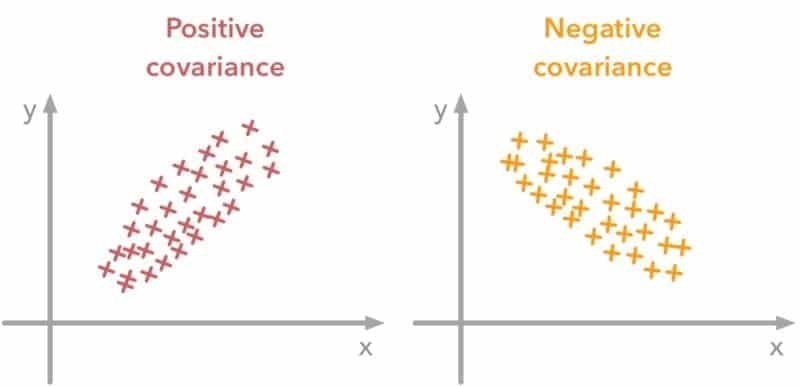
This question serves as a primary role in data science interview questions as well as statistics interview questions, and so it is very important for you to know how to tactfully answer this. To simply put it in a few words, variance and covariance are just two mathematical terms, and they are used very frequently in statistics.
Some data analytics interview questions also tend to include this difference. The main dissimilarity is that variance works with the mean of numbers and refers to how spaced out numbers are concerning the mean whereas covariance, on the other hand, works with the change of two random variables concerning one another.
Q-12: What is the difference between the Do Index, Do While and the Do until loop? Give examples.

The chance of this question being asked to you in your data science and data analyst interview is extremely high. Now firstly, you have to be able to explain to the interviewer what you understand by a Do loop. The job of a Do loop is to execute a block of code recurrently based on a certain condition. The image will give you a general idea of the workflow.
- Do Index loop: This uses an index variable as a start and stops value. Until the index value reaches its final value, the SAS statements get executed repeatedly.
- Do While loop: This loop works by using a while condition. When the condition is true, this loop keeps executing the block of code until the condition becomes false and is no longer applicable, and the loop terminates.
- Do Until Loop: This loop uses an until condition which executes a block of code when the condition is false and keeps executing it until the condition becomes true. A condition that is true causes the loop to get terminated. This is just the opposite of a do-while loop.
Q-13: What are the five V’s of Big Data?
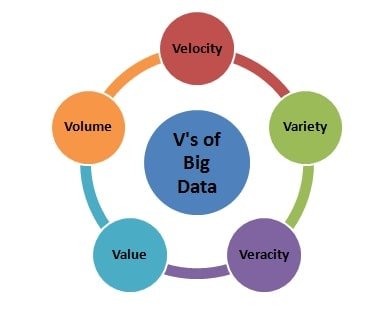
The answer to this Data Science interview question would be a little detailed with a focus on different points. The five V’s of big data are as follows:
- Volume: Volume represents the amount of data that is increasing at a high rate.
- Velocity: Velocity determines the rate at which data grows in which social media plays a huge role.
- Variety: Variety denotes the different data types or formats of data users such as text, audio, video, etc.
- Veracity: Large volumes of information are hard to deal with, and subsequently, it brings inadequacy and irregularity. Veracity alludes to this evasion of accessible information, which emerges from the overwhelming volume of information.
- Value: Value refers to the transformation of data into value. Business companies can generate revenue by turning these accessed big data into values.
Q-14: What is ACID property in a database?
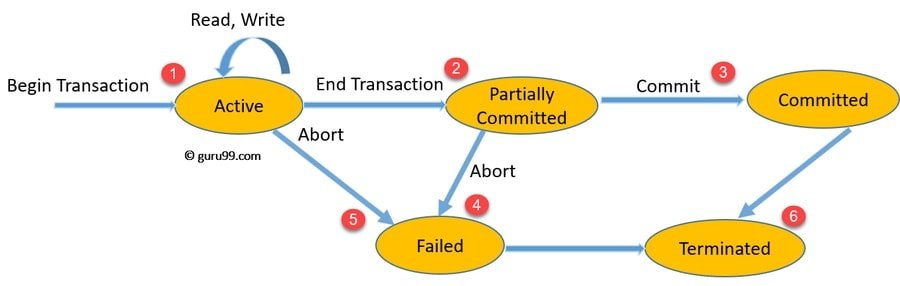
In a database, the reliable processing of the data transactions in the system is ensured using this property. Atomicity, Consistency, Isolation, and Durability is what ACID denotes and represents.
- Atomicity: This alludes to the exchanges which are either totally effective or have flopped totally. For this situation, a solitary activity is alluded to as an exchange. In this manner, regardless of whether a solitary exchange fizzles, at that point, the whole exchange is influenced.
- Consistency: This feature ensures that all the validation rules are met by the data, and this makes sure that without completing its state, the transaction never leaves the database system.
- Isolation: This function allows transactions to be independent of each other as it keeps the transactions separated from each other until they are completed.
- Durability: This ensures the submitted exchanges are rarely lost and in this manner, ensures that regardless of whether there is an unusual end like a power misfortune or crash, the server can recuperate from it.
Q-15: What is Normalization? Explain different types of Normalization with advantages
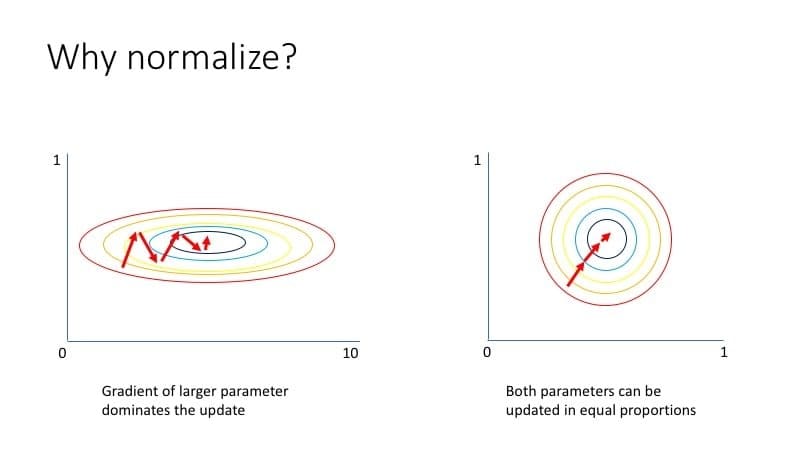
Standardization is the way toward sorting out information which maintains a strategic distance from duplication and repetition. It comprises of numerous progressive levels called normal forms, and every normal form relies upon the past one. They are:
- First Normal Form (1NF): No repeating groups within the rows
- Second Normal Form (2NF): Every non-key (supporting) column value is dependent on the whole primary key.
- Third Normal Form (3NF): Solely depends on the primary key and no other supporting column.
- Boyce- Codd Normal Form (BCNF): This is the advanced version of 3NF.
Some advantages are:
- More compact database
- Allows easy modification
- Information found more quickly
- Greater flexibility for queries
- Security is easier to implement
Q-16: List the differences between supervised and unsupervised learning.
You would also get data science interview questions like this in your interview. You may answer this like:
- In Supervised learning, the input data is labeled, and in unsupervised learning, it is unlabeled.
- Supervised learning uses a training dataset, whereas unsupervised learning uses the input data set.
- Supervised learning is used for prediction, and the latter is used for analysis.
- The first type enables classification and regression and the second one enables Classification, Density Estimation, & Dimension Reduction
Q-17: What do you understand by the statistical power of sensitivity, and how do you calculate it?
We use sensitivity, usually, to approve the exactness of a classifier, that is, Logistic, SVM, RF, and so forth. The equation for ascertaining affectability is “Predicted True Events/Total Events.” Genuine occasions, for this situation, are the occasions that were valid, and the model had additionally anticipated them as evidence.
Q-18: What is the importance of having a selection bias?
To answer this data science interview question, you can first state that Selection bias is a kind of error that occurs when a researcher decides who is going to be studied. That is when there is no appropriate randomization achieved while selecting groups or data to be analyzed or even individuals. We should consider the selection bias on the grounds that something else, a few finishes of the investigation may not be precise.
Q-19: Give some situations where you will use an SVM over a Random Forest Machine Learning algorithm and vice-versa.
Both SVM and Random Forest are utilized in arrangement issues.
- Now, if your data is clean and outlier free, then you should go for SVM, and if it is the opposite, that is, your data might contain outliers, then the best choice would be to use Random Forest.
- The importance of variable is often provided by Random Forest, and thereby if you want to have variable importance, then choose the Random forest machine learning algorithm.
- Sometimes we are constrained with memory, and in that case, we should go for the random forest machine learning algorithm as SVM consumes more computational power.
Q-20: How do data management procedures, like missing data handling, make selection bias worse?
One of the essential undertakings of a data scientist is to treat missing numbers before beginning an information examination. There are various methods for missing value treatment, and if not done properly, it could hamper the selection bias. For example,
- Complete Case Treatment: This method is when only one value is missing, but you remove an entire row in the data for that. This could cause a choice inclination if your characteristics are not missing capriciously, and they have a particular model.
- Available case analysis: Let’s say you are removing the missing values from variables that are needed to calculate the correlation matrix for data. In this case, if your values are coming from population sets, then they will not be fully correct.
- Mean Substitution: In this method, the mean of other available values is calculated and placed in the place of the missing values. This method is not the best one to choose as it might make your distribution biased. Thus, if not picked effectively, various information the board methods may incorporate selection bias in your information.
Q-21: What is the advantage of performing dimensionality reduction before fitting an SVM?
You can find this question commonly in all the lists of Data science interview questions. The candidate should answer this question as – Support Vector Machine Learning Algorithm performs more efficiently in the concentrated space. Therefore, if the number of features is large when compared to the number of observations, it is always beneficial to perform dimensionality reduction before fitting an SVM.
Q-22: What are the differences between overfitting and underfitting?
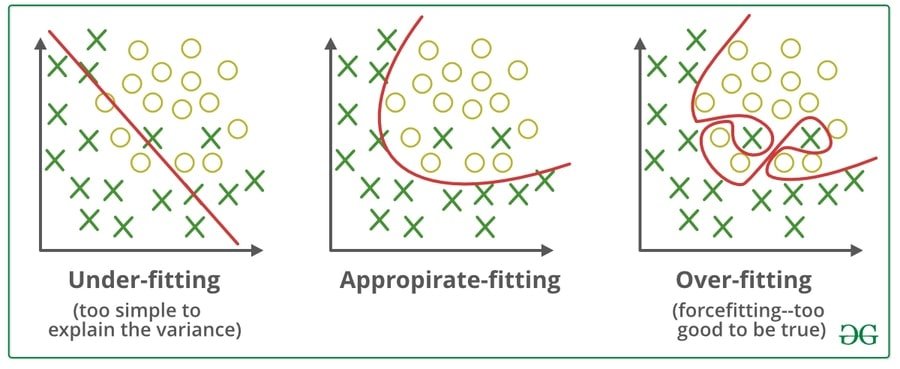
In statistics and machine learning, models can make reliable predictions on general untrained data. This is possible only if a model is fit to a set of training data, and this is considered as one of the major tasks.
In machine learning, a model that models the training data too well is referred to as overfitting. This occurs when a model acquires the details and noises in the training set and takes it as a piece of important information for the new data. This contrarily impacts the establishment of the model as it gets these irregular changes or sounds as vital ideas for the new model, while it doesn’t have any significant bearing to it.
Underfitting occurs when the fundamental trend of the data cannot be captured by a statistical model or machine learning algorithm. For instance, underfitting would happen when fitting a direct model to non-straight data. This sort of model additionally would have poor predictive performance.
Q-23: What is Back Propagation and Explain it’s Working.
Backpropagation is a preparation calculation, and it is utilized for multilayer neural systems. In this strategy, we circulate the blunder from one finish of the system to all loads inside the system and accordingly permitting effective calculation of the inclination.
It works in the following steps:
- Training Data is propagated forward
- Using output and target, derivatives are computed
- Back Propagate for computing derivative of the error concerning output activation
- Using previously calculated derivatives for output
- The weights are updated
Q-24: Differentiate between Data Science, Machine Learning, and AI.
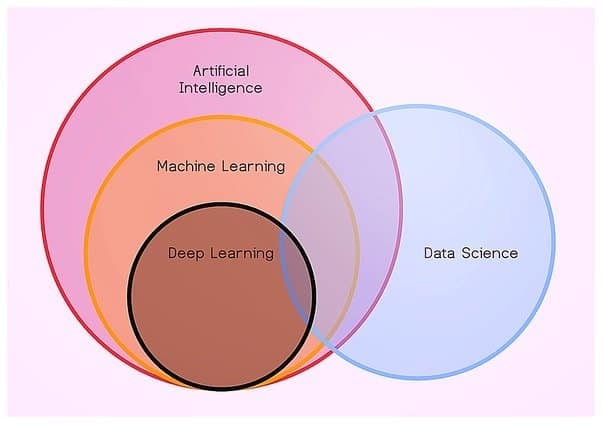
Simply placed, machine learning is the process of learning from data over time, and therefore, it is the link that connects Data Science and ML/AI. Data science can get results and solutions for specific problems with the help of AI. However, machine learning is what helps in achieving that goal.
A subset of AI is machine learning, and it focuses on a narrow range of activities. The association of machine learning with other disciplines like cloud computing and big data analytics is also done by it. A more practical application of machine learning with a complete focus on solving real-world problems is nothing else but data science.
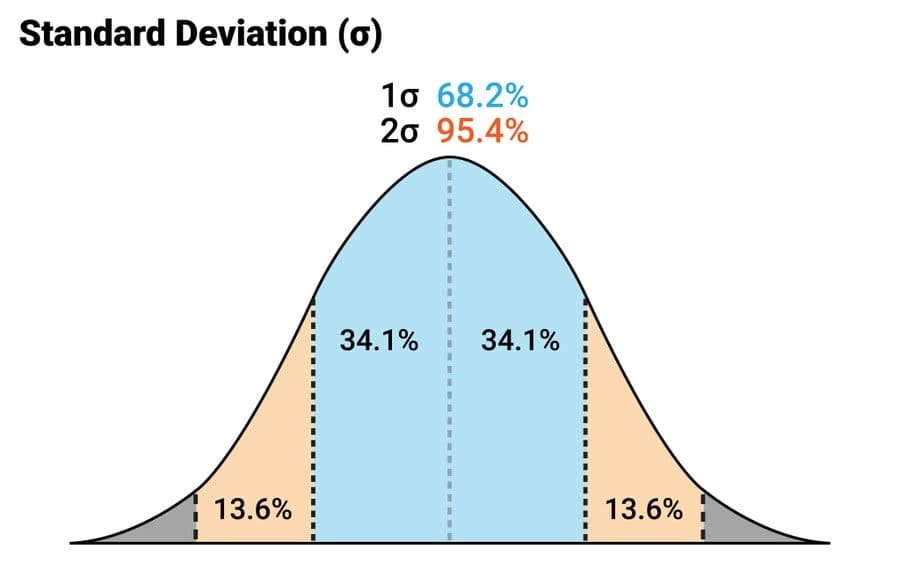
Q-25: What are the characteristics of normal distribution?
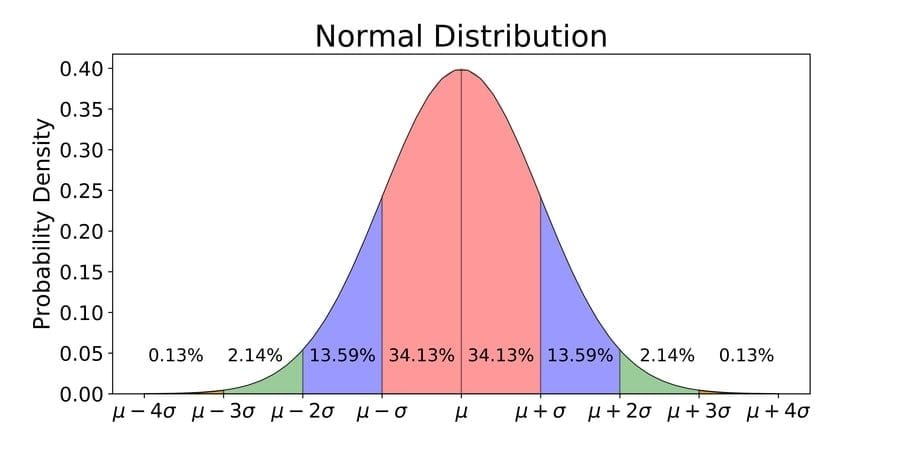
At the point when information is conveyed around a focal incentive with no sort of predisposition to one side or right, which is the standard case, we consider it normal distribution. It frames a chime molded bend. The irregular factors are dispersed as an even chime formed bend or different words; they are balanced around it’s inside.
Thereby, the characteristics of the normal distribution are that they are symmetric unimodal and asymptotic, and the mean, median, and mode are all equal.
Q-26: What do you understand by Fuzzy merging? Which language will you use to handle it?
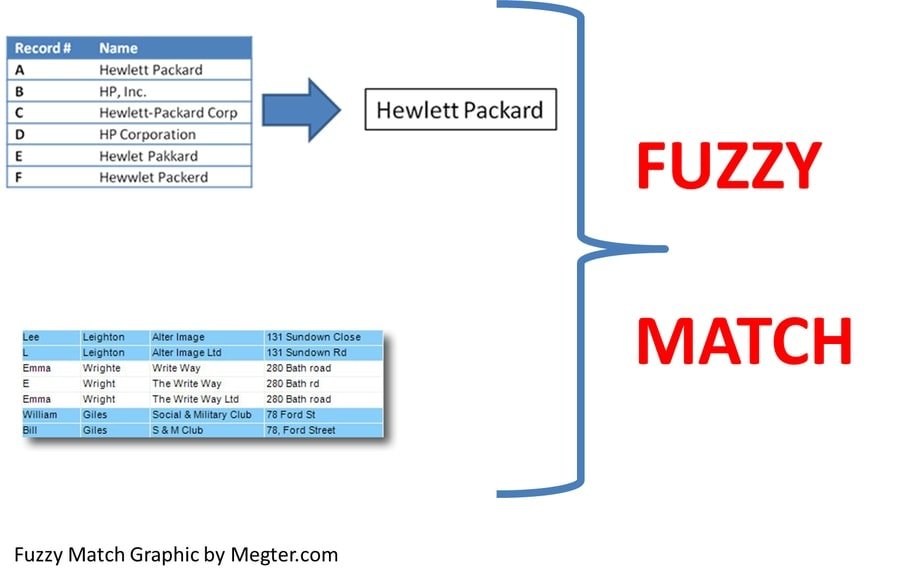
The most applicable response for this data science interview question would be that fuzzy merges are those who merge the values or data that are approximately the same — for instance, converging on names which roughly have comparable spelling or even occasions that are inside four minutes of one another.
The language used to handle fuzzy merging is SAS (Statistical Analysis System), which is a computer programming language used for statistical analysis.
Q-27: Differentiate between univariate, bivariate and multivariate analysis.
These are the expressive examination systems that can be separated depending on the number of factors that they are managing at a given purpose of time. For example, an analysis based on a single variable is referred to as univariate analysis.
In a scatterplot, where the difference between two variables is handled at a time is referred to as bivariate analysis. An example can be analyzing the volume of sales and spending at the same time. The multivariate examination manages the investigation that reviews multiple factors for understanding the impact of those factors on the reactions.
Q-28: What is the difference between Cluster and Systematic Sampling?
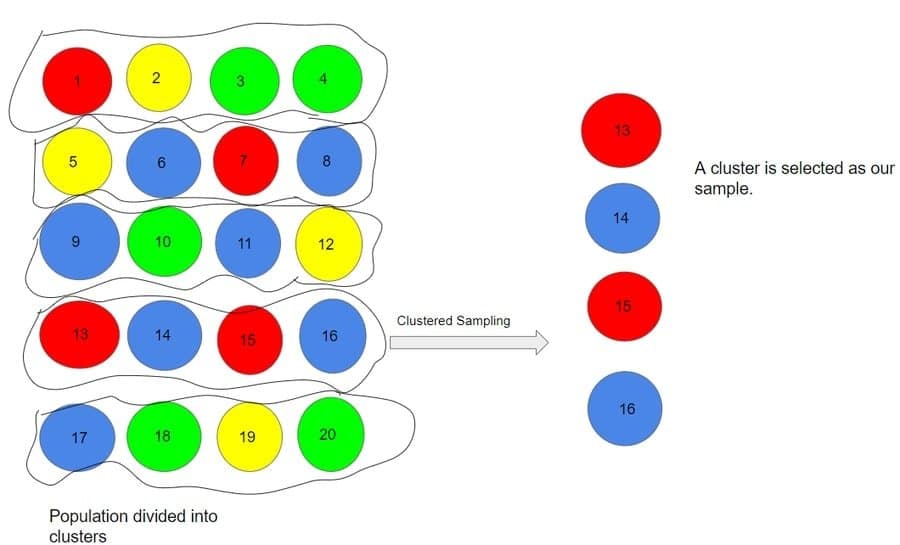
This question is very commonly asked in both a data science interview as well as a statistics interview. Cluster sampling is a technique that is commonly used when studying for a target population that is spread widely over an area, and thereby, using simple random sampling makes the procedure much complicated.
Systematic sampling, then again, is a factual system where there is an arranged examining outline from which components are chosen. In this sampling method, a circular manner is maintained for progressing the list of samples and once it comes to the end of the list, it is progressed from the starting back again.
Q-29: What are an Eigenvalue and Eigenvector?
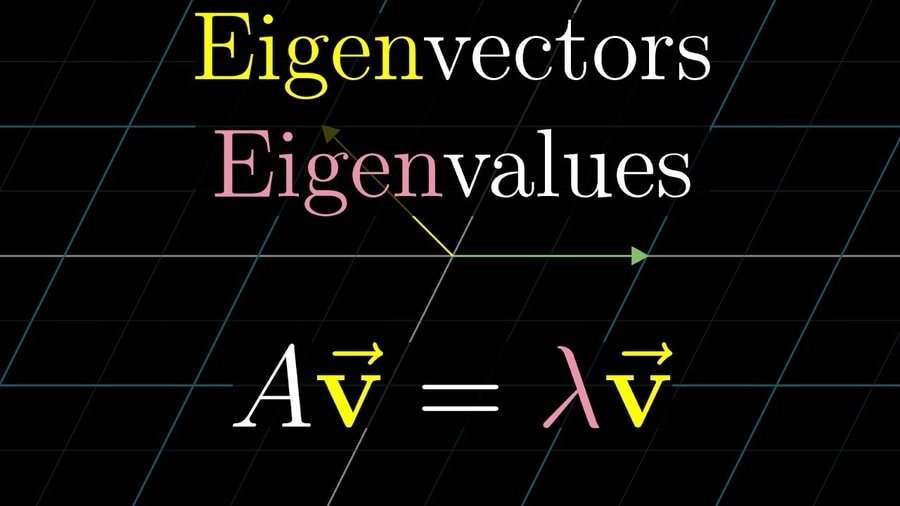
To answer this interview question, you can go like, eigenvectors are used for understanding linear transformations, and it tells us in which specific direction a particular linear transformation acts by flipping, compressing or stretching. In data analysis, the eigenvectors for a correlation or covariance matrix is usually calculated.
The eigenvalue is alluded to how emphatically a straight change acts toward that eigenvector. It can likewise be known as the factor by which the pressure happens.
Q-30: What is statistical power analysis?
Statistical power analysis deals with type II errors – the error that can be committed by a researcher while conducting tests of hypothesis. The fundamental motivation behind this investigation is to assist analysts in finding the littlest example size for recognizing the impact of a given test.
The fundamental motivation behind this investigation is to assist analysts in finding the littlest example size for recognizing the impact of a given test. The small sample size is much preferred, as larger samples cost more. Smaller samples also help to optimize the particular testing.
Q-31: How can you assess a good logistic model?
To exhibit your insight into this data science interview question, you can list a couple of strategies to survey the consequences of a calculated relapse examination. Some methods include:
- To look at the true negatives and false positives of the analysis using a classification matrix.
- Lift compares the analysis with random selection, and this again helps to assess the logistic model.
- Events that are happening and those that are not happening should be able to be differentiated by a logistic model, and this ability of the model is identified by concordance.
Q-32: Explain about the box cox transformation in regression models.
Scenario-based data science interview questions such as the above can also appear in your data science or statistics interview. The response would be that the box-cox transformation is a data transformation technique that turns a non-normal distribution into a normal shape or distribution.
This comes from the fact that the assumptions of an ordinary least squares (OLS) regression might not be satisfied by the response variable of a regression analysis. This prompts the residuals bending as the forecast increments or following a skewed distribution. In such cases, it is necessary to bring in the box-cox transformation to transform the response variable so that the required assumptions are met by the data. Box cox change enables us to run a more extensive number of tests.
Q-33: What are the various steps involved in an analytics project?
This is one of the most common questions asked in a data analytics interview. The steps involved in an analytics project are as follows in a serial manner:
- To understand the business problem is the first and most important step.
- Explore the given data and familiarize with it.
- Distinguish exceptions, treat missing qualities, and change the factors. This progression will set up the information for demonstrating.
- This is a bit time-consuming step as it is iterative, meaning that after data preparation, the models are run, the corresponding results are analyzed, and the approaches are tweaked. These are done continuously until the best possible outcome is reached.
- Next, the model is approved utilizing another informational collection.
- The model is then actualized, and the outcomes are followed to dissect the presentation of the model after some time.
Q-34: During analysis, how do you treat missing values?
At first, the variables containing missing values are identified and along with with with with that the extent of the missing value. The analyst should then try to look for patterns, and if a pattern is identified, the analyst should focus on it as this could lead to meaningful business insights. On the off chance that no such examples are distinguished, the missing qualities are simply substituted with the mean or middle qualities, and if not, they are simply overlooked.
In the event that the variable is all out, the missing worth is appointed default esteem. In the event that we have a dispersion of information coming, you should give the mean an incentive for typical conveyance. In some cases, almost 80% of the values in a variable might be missing. In that situation, just drop the variable instead of trying to fix the missing values.
Q-35: What is the difference between Bayesian Estimate and Maximum Likelihood Estimation (MLE)?
This entry of data science interview questions is very important for your upcoming interviews. In Bayesian estimate, we have prior knowledge about the data or problem that we will work with, but the Maximum Likelihood Estimation(MLE) does not take prior into consideration.
The parameter maximizing the likelihood function is estimated by MLE. With respect to the Bayesian estimate, its primary point is to limit the back expected estimation of a misfortune work.
Q-36: How can outlier values be treated?
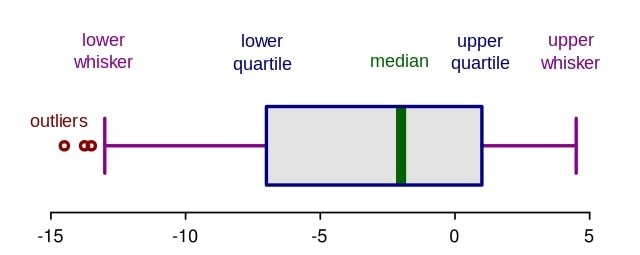
Anomaly esteems can be related to the assistance of a graphical investigation strategy or by utilizing univariate. For fewer exception esteems, they are evaluated exclusively and fixed, and concerning countless anomalies, the qualities are generally substituted with either the 99th or the first percentile esteems. But we have to keep in mind that not all extreme values are outlier values. The two most common ways to treat outlier values-
- Changing the value and bringing it within a range
- Removing the value completely
Adding the last piece of information heights up your answer to this data science interview question to a new level.
Q-37: What is Statistics? How many types of statistics are there?
Statistics is a part of science that alludes to the assortment, examination, translation, and introduction of huge numbers of numerical information. It gathers information from us and things we observe and analyses it to bring meaning to it. An example can be a family counselor using statistics to describe a patient’s certain behavior.
Statistics are of two types:
- Descriptive Statistics – used for summarizing observations.
- Inferential Statistics – used for interpreting the meaning of the descriptive stats.
Q-38: What is the difference between skewed and uniform distribution?
The most applicable response to this question would be that when the perceptions in a dataset are similarly spread over the scope of dispersion; at that point, it is known as a uniform distribution. In uniform distribution, no clear perks are present.
Disseminations that have more discernments on one side of the chart than the other are implied as skewed appropriation. In some cases, there are more values on the right than on the left; this is said to be skewed left. In other cases, where there are more observations on the left, it is said to be right-skewed.
Q-39: What is the purpose of statistically analyzing study data?
Before diving into answering this data analytics interview question, we must explain what really statistical analysis is. Not only will this question prepare you for your data science interview, but it is also a master question for your statistics interview. Now, statistical analysis is the science that helps to discover underlying patterns and trends of data by collecting, exploring, and presenting large amounts of data.
The sole purpose behind statistically analyzing study data is to get improved and more reliable results, which are based entirely on our thoughts. For example:
- Network resources are optimized by communication companies with the use of statistics.
- Government agencies around the world depend greatly on statistics for understanding their businesses, countries, and their people.
Q-40: How many types of distributions are there?
This question is applicable to both the data science and statistics interview. The various types of distributions are Bernoulli Distribution, Uniform Distribution, Binomial Distribution, Normal Distribution, Poisson Distribution, Exponential Distribution.
Q-41: How many types of variables are there in statistics?
There are many variables in statistics and they are Categorical variable, Confounding variable, Continuous variable, Control variable, Dependent variable, Discrete variable, Independent variable, Nominal variable, Ordinal variable, Qualitative variable, Quantitative variable, Random variables, Ratio variables, Ranked variables.
Q-42: What is Descriptive and Inferential statistics?

This is one of the favorite questions of interviewers and therefore be assured to be asked this particular data science interview question. Descriptive Statistics are graphic coefficients that empower one to condense a lot of information.
Descriptive Statistics are of two sorts, proportions of focal propensity and proportions of spread. Measures of central tendency include meaning, median, and mode. Measures of spread include standard deviation, variance, minimum and maximum variables, kurtosis, and skewness.
Inferential Statistics collect random samples from an entire data set. Inferences are made about the population. Inferential Statistics is useful because collecting measurements on every member of a large population is tiresome.
For example, there is a material X, whose items’ diameters have to be measured. 20 such items’ diameters are measured. The average diameter of the 20 items is considered as a rough measurement for all items of material X.
Q-43: Define the following terms: Mean, Mode, Median, Variance, Standard Deviation.
To answer this statistics interview question, you can say that –
- The “mean” is the central tendency value that is calculated by summing up all the data points, which is then divided by the total number of points.
- The mode is the data value that repeats most often within a data set.
- Observations are organized in rising request. On the off chance that there is an odd number of perceptions, the median is the center value. For a much number of perceptions, the median is the normal of the two center qualities.
- Standard deviation is a measure of the dispersion of values within a data set. The lower the standard deviation, the closer the values are to the mean, and vice versa.
- Variance is the squared value of the standard deviation.
Q-44: What is Deep learning?
The coverage of the best data analyst interview questions would likewise incorporate this big data interview question. Deep learning Profound learning is a subfield of AI, which is a subfield of computerized reasoning or artificial intelligence. Deep learning depends on the structure and capacity of the human cerebrum, called artificial neural networks.
Algorithms can be built by the machine alone, which are better and easier to use than traditional algorithms. Deep learning requires fast computers and a huge amount of data for efficient training of large neural networks. The more data fed into the computer, the more accurate the algorithm, and the better the performance.
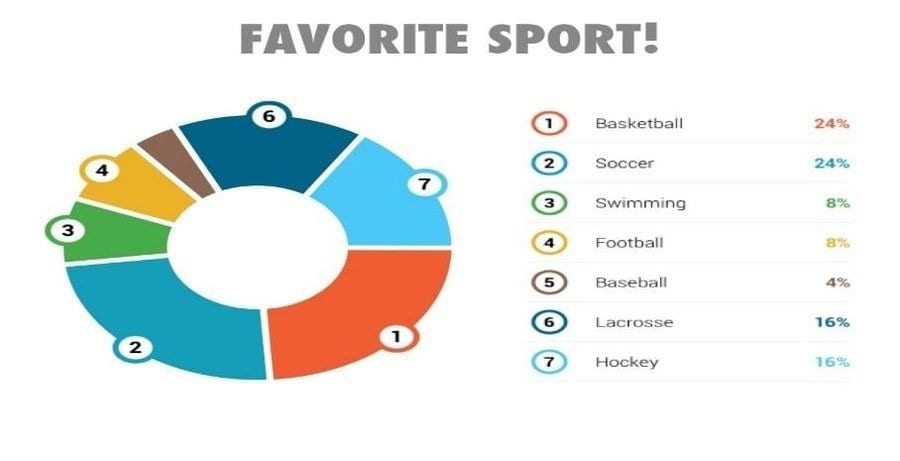
Q-45: What is Data visualization with different Charts in Python?
In this Data Analytics interview question, data visualization is a technique by which data in Python is represented in graphical form. A large data set can be summarized in a simple and easy-to-understand format. An example of a Python chart would be a histogram of age group and frequency.
Another example is a pie chart representing the percentage of people responding to their favorite sports.
Q-46: In Your Opinion, What Skills and Qualities Should a Successful Data Analyst Have?
This is one of the most basic yet very important data science as well as data analyst interview questions. Interviewers never seem to miss this particular data science interview question. To answer this data science interview question, you must be very clear and specific.
Firstly, a successful data analyst should be very creative. By this, it means that he/she should always be wanting to experiment with new things, remain flexible, and simultaneously solve various kinds of problems.
Secondly, staying curious all the time is a very important characteristic a data analyst should have as almost all the top-notch data analysts have the question of “why” behind the numbers.
Thirdly, they should have a strategic perspective, meaning that they should be able to think beyond a tactical level. They should likewise have successful relational abilities, one that enables them to change significant information into edible bits of knowledge for every one of their crowds.
Q-47: How would you transform unstructured data into structured data?
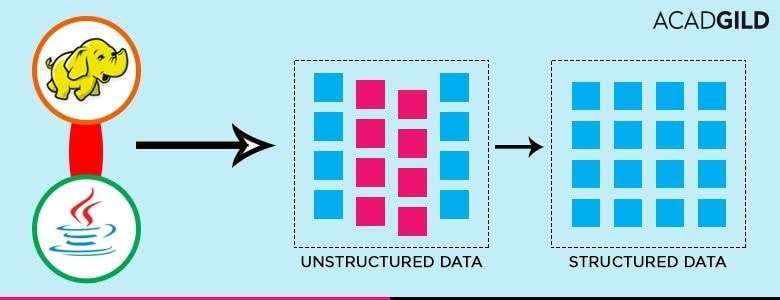
In the Data Science interview question, machine learning algorithms are a helpful mechanism in turning unstructured data into structured data. First, unstructured data is labeled and categorized through machine learning. Secondly, data is cleaned – errors, such as typing errors and formatting issues, are identified and fixed.
Besides, an observation of the trend of errors can help in making a machine learning model that can automatically correct errors. Thirdly, the data is modeled – various statistical relationships are identified within the data values of the whole data set. Fourthly, data is visualized in the form of graphs and charts.
In the following diagram, it is observed that the elephant picture is differentiated from the cup by machine learning, perhaps through pixel calculation, color properties, etc. The data that describes the features of each unique picture is stored and further used as structured data.
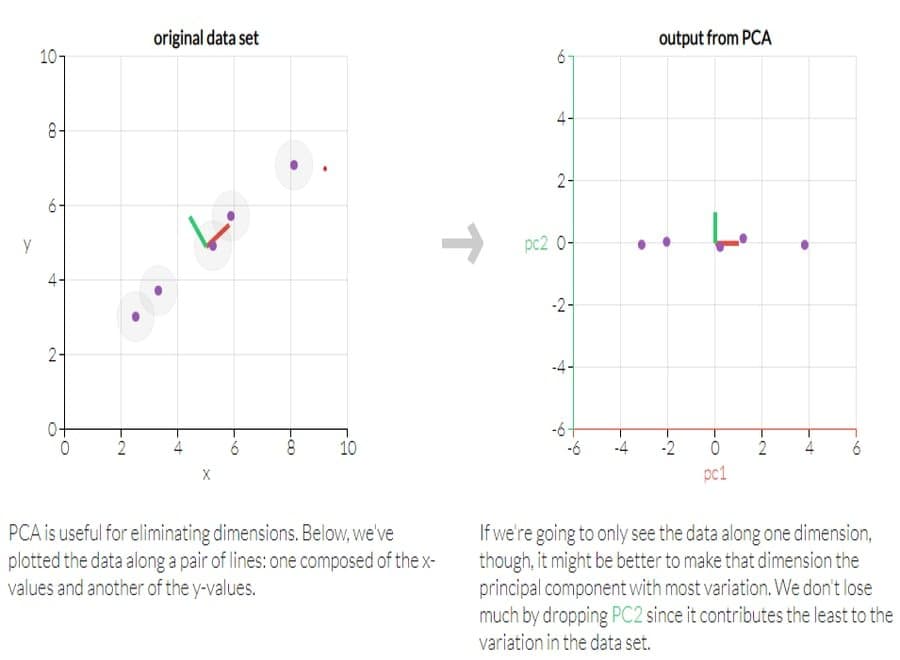
Q-48: What is PCA? ( Principal component analysis ).
This is a frequently asked Statistics interview question. PCA is a system of diminishing the dimensionality of the variable space by addressing it with a few uncorrelated components that catch a huge segment of the vacillation. PCA is useful due to its ease of reading, analyzing, and interpreting a reduced data set.
In the figure below, one axis is a dimension created by combining two variables as one. The hub is suggested as head segments.
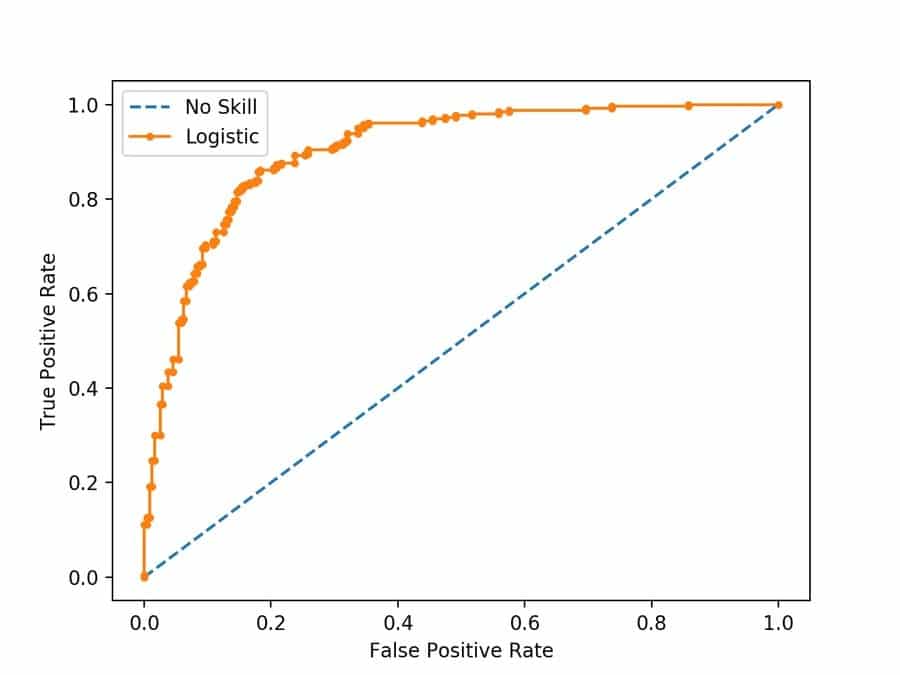
Q-49: What is the ROC curve?
ROC represents Receiver Operating Characteristic. It is a kind of bend. ROC curve is utilized to discover the precision of paired classifiers. The ROC bend is a 2-D bend. Its x-hub addresses the False Positive Rate (FPR), and its y-hub addresses the True Positive Rate (TPR).
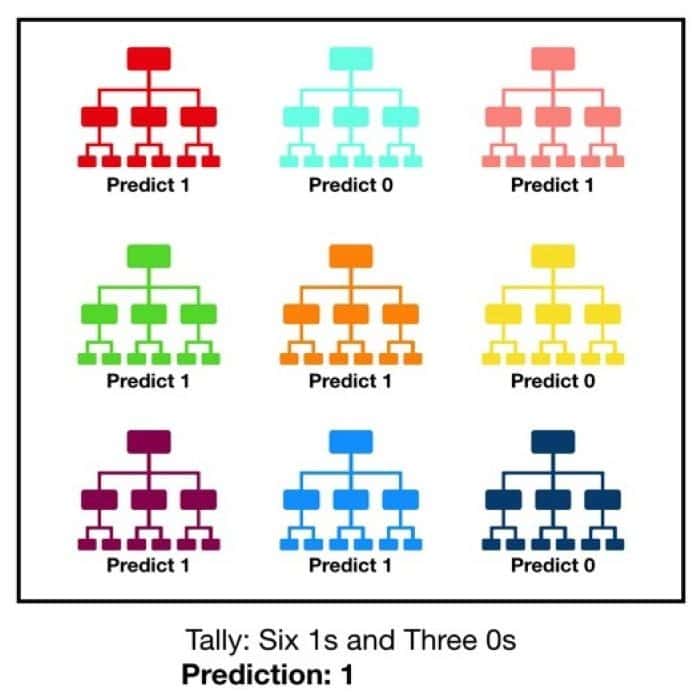
Q-50: What do you understand by a random forest model?
This is much of the time posed inquiry in a data analyst interview. Decision trees form the structure squares of a random forest. A large number of individual decision trees operate as an ensemble. Each individual tree makes a class prediction. The trees should have different sets of data and also different features to make decisions, thus introducing randomness. The class that has the highest vote is our model’s prediction.
Q-51: Mention the responsibilities of a Data analyst.
This Data Analytics interview question asks for a brief description of the role of a data analyst. First, a data analyst has to know about the organizational goals by effectively communicating with the IT team, Management, and Data Scientists. Secondly, raw data is collected from the company database or external sources, which are then manipulated through mathematics and computational algorithms.
Thirdly, various correlations between variables have to be deduced in complicated datasets to understand the short term and long-term trends. Finally, visualizations such as graphs and bar charts help to form decisions.
Q-52: Mention what is the difference between data mining and data profiling?
This is a Data Science interview question that asks for describing the two subfields.
| Data Mining | Data Profiling |
| Data mining extracts a specific pattern from large data sets. | Data profiling is the way toward arranging huge information so as to decide helpful bits of knowledge and choices. |
| The study of data mining involves the intersection of machine learning, statistics, and databases. | The study of data profiling requires knowledge of computer science, statistics, mathematics, and machine learning. |
| The yield is information design. | The output is a verified hypothesis on the data. |
Q-53: Explain what should be done with suspected or missing data?

This is a Statistics interview question that asks to solve the missing data problem by implementing a few solution methods. First, if there is a small number of null values in a large dataset, the null values can be dropped. Secondly, linear interpolation can be applied if the data trend follows a time series. Thirdly, for seasonal data, a graph can have both seasonal adjustment and linear interpolation.
Fourthly, linear regression can be used, which is a long method where several predictors of the variables with missing numbers are identified. Best predictors are chosen as independent variables in the regression model, whereas the variable with missing data is the dependent variable. An input value is substituted to calculate the missing value.
Fifthly, depending on the symmetry of data set, mean, median, or mode can be considered to be the most likely value of the missing data. For example, in the following data, mode = 4 can be applied as a missing value.
Q-54: Explain what is collaborative filtering?
This is a commonly asked Big Data interview question that concerns consumer choice. Collaborative filtering is the process of building personalized recommendations in a search engine. Some big companies that use collaborative filtering include Amazon, Netflix, iTunes, etc.
Algorithms are used to make predictions of users’ interest by compiling preferences from other users. For example, a shopper might find the recommendation of buying a white bag at an online shop based on her previous shopping history. Another example is when people of similar interests, such as sports, are recommended a healthy diet, as illustrated below.
Q-55: What is a hash table?
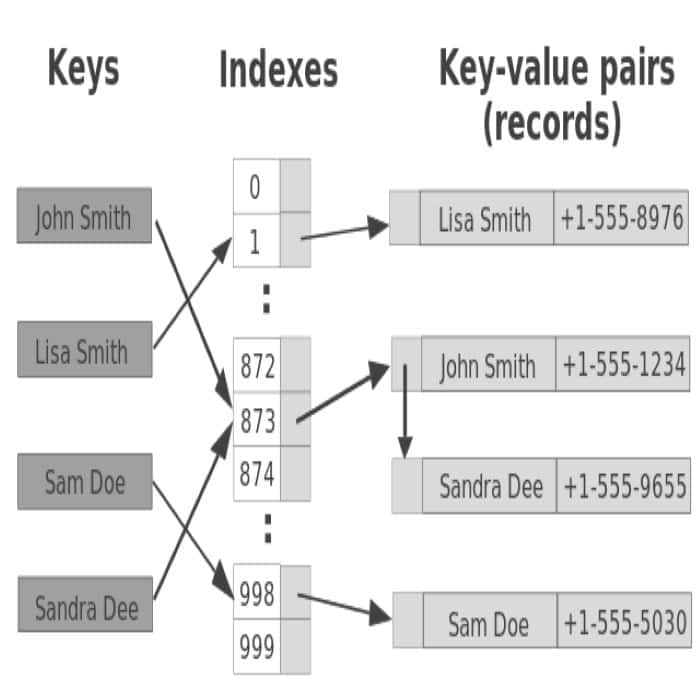
This Data Analyst interview question asks for a brief description of the hash table and its uses. Hash tables actualize maps and information structures in most normal programming dialects. Hash table is an unordered assortment of key-esteem sets, where each key is remarkable.
The key is sent to a hash function that performs arithmetic operations on it. Lookup, insert, and delete functions can be implemented efficiently. The calculated result is called hash, which is the index of the key-value pair in the hash table.
Q-56: Explain what is imputation? List out different types of imputation techniques?
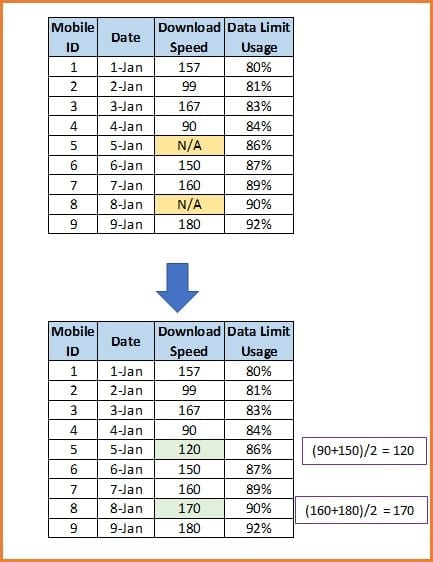
Imputation is the way toward remedying mistakes, by assessing and filling in missing qualities in a dataset.
In interactive treatment, a human editor adjusts data by contacting the data provider, or by replacing data from another source, or by creating value based on subject matter expertise. In deductive attribution, the method of reasoning about the association between factors is used to fill in missing characteristics. Example: a value is derived as a function of other values.
In model-based imputation, missing value is estimated using assumptions on data distribution, which includes mean and median imputation. In donor-based imputation, value is adopted from an observed unit. For example: if a tourist who is filling up a form with missing data has a similar cultural background to other tourists, it can be assumed that the missing data from the tourist is similar to others.
Q-57: What are the important steps in the data validation process?
This is a Data Science as well as a big data interview question that asks for a brief explanation for each step of data validation. First, the data sample has to be determined. Based on the large size of the dataset, we have to pick a large enough sample. Secondly, in the data validation process, it must be ensured that all required data is already available in the existing database.
Several records and unique IDs are determined, and source and target data fields are compared. Thirdly, the data format is validated by determining changes in source data to match the target. Incongruent checks, copy information, inaccurate organizations, and invalid field esteems are rectified.
Q-58: What are hash table collisions? How is it avoided?
This is a Data Science interview question that asks to deal with hash table collisions. A hash table collision is where a recently embedded key maps to a previously involved opening in the hash table. Hash tables have a small number for a key that has a big integer or string, so two keys may result in the same value.
Collisions are avoided by two methods. The first method is chained hashing. The elements of a hash table are stored in a set of linked lists. All colliding elements are kept in one linked list. The list head pointers are usually stored in an array. The second method is to open to address hashing. The hashed keys are put away in the hash table itself. The colliding keys are allocated distinct cells in the table.
Q-59: What is a Pivot Table, and what are the different sections of a Pivot Table?
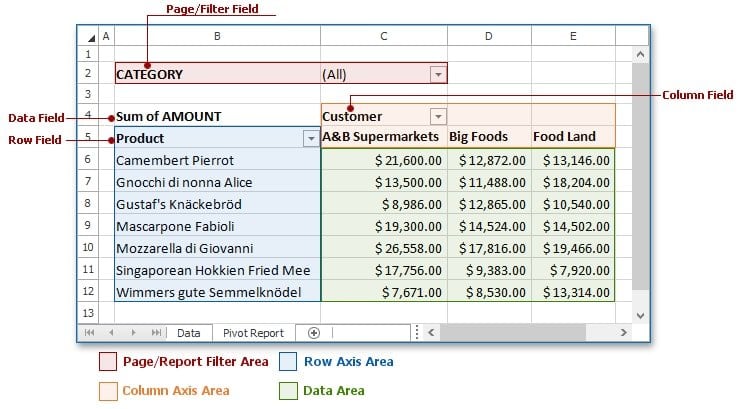
A pivot table is a method of information handling. It is a statistical table that abridges information from a progressively broad table – database, spreadsheets, and business insight program. A pivot table incorporates totals, midpoints, and other measurable qualities that are assembled in a significant manner. A pivot table allows a person to arrange and rearrange, i.e., pivot, statistical information in order to show useful insights into the collected data.
There are four sections. The values area calculates and counts data. These are measurement data. An example is the Sum of Revenue. Row area shows a row-oriented perspective. Data can be grouped and categorized under row headings.
Example: Products. The column area shows a column-oriented perspective of unique values. Example: Monthly Expenditure. The filter area is at the highest point of the pivot table. The filter is applied for easy search of a particular kind of data. Example: Region.
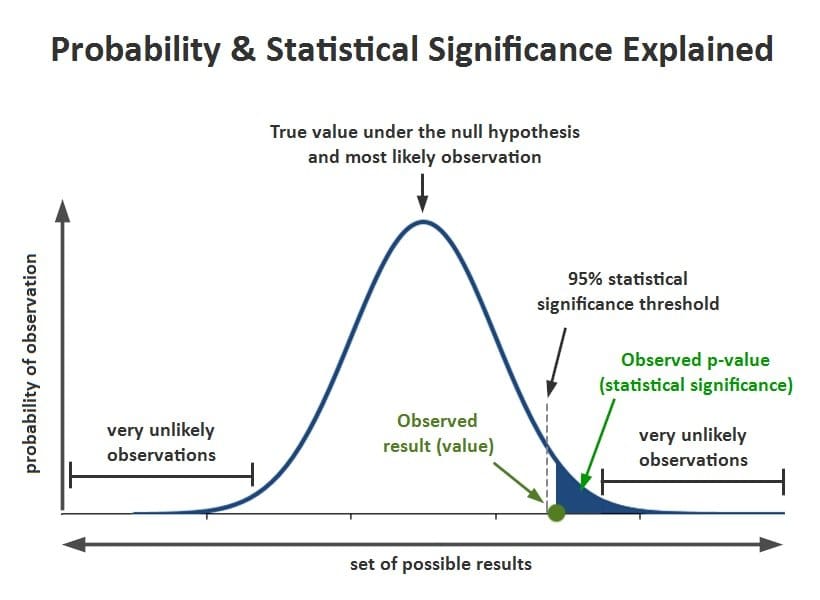
Q-60: What does P-value signify about the statistical data?
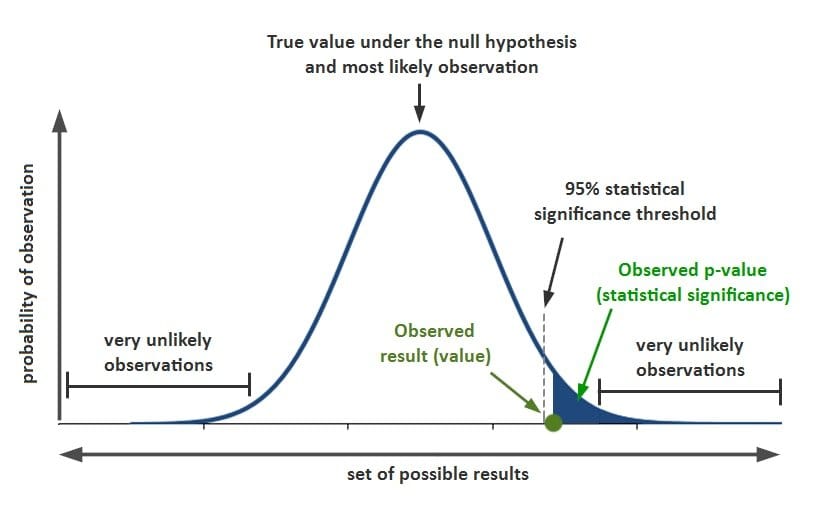
If you are heading towards becoming a data analyst, this question is very important for your interview. It is also a crucial topic for your Statistics interview as well. This question asks about how to implement p-value.
At the point when a speculation test is performed in measurements, a p-value decides the noteworthiness of the outcomes. Hypothesis tests are used to test the validity of a claim that is made about a population. This claim that is on trial is called the null hypothesis.
If the null hypothesis is concluded to be untrue, the alternative hypothesis is followed. The proof in the preliminary is the information got and the insights that accompany it. All speculation tests ultimately utilize a p-worth to gauge the quality of the proof. The p-value is a number between 0 and 1 and interpreted in the following way:
- A small p-value (typically ≤ 0.05) indicates strong evidence against the null hypothesis, so the null hypothesis is rejected.
- A huge p-value (> 0.05) demonstrates powerless proof against the invalid theory, so the invalid speculation is not dismissed.
- P-values near the cutoff (0.05) are viewed as peripheral. The readers of the information then draw their own conclusion.
Q-61: What is Z value or Z score (Standard Score), how it’s useful?
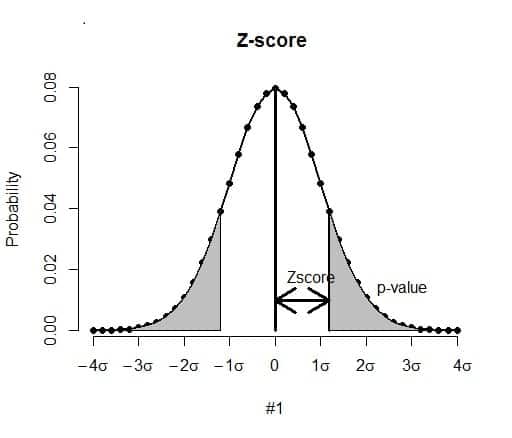
This entry is also one of the top big data interview questions. The answer to this data science interview question would be a little detailed, with a focus on different points. A z-score is the number of standard deviations from the mean a data point is. It is additionally a proportion of what number of standard deviations beneath or over the populace means a crude score is.
A z-score can be set on a typical dissemination bend. Z-scores go from – 3 standard deviations (which would tumble to the most distant left of the typical conveyance bend) up to +3 standard deviations (which would tumble to the furthest right of the ordinary dispersion bend). The mean and standard deviation need to be known in order to calculate z-score.
Z-scores are an approach to contrast results from a test with an “ordinary” populace. Results from tests or studies have a large number of potential outcomes and units. In any case, those outcomes can regularly appear to be pointless.
For instance, realizing that somebody’s weight is 150 pounds may be great data, yet to contrast it with the “normal” individual’s weight, taking a gander at a tremendous table of information can be overpowering. A z-score can tell where that individual’s weight is contrasted with the normal populace’s mean weight.
Q-62: What is T-Score. What is the use of it?
This is a Statistics interview question asked when it is necessary to work with a small sample size. The t score takes an individual score and transforms it into a standardized form, i.e., one which helps to compare scores. T score is utilized when the populace standard deviation is obscure, and the test is little (under 30). So, the sample’s standard deviation is used to calculate t score.
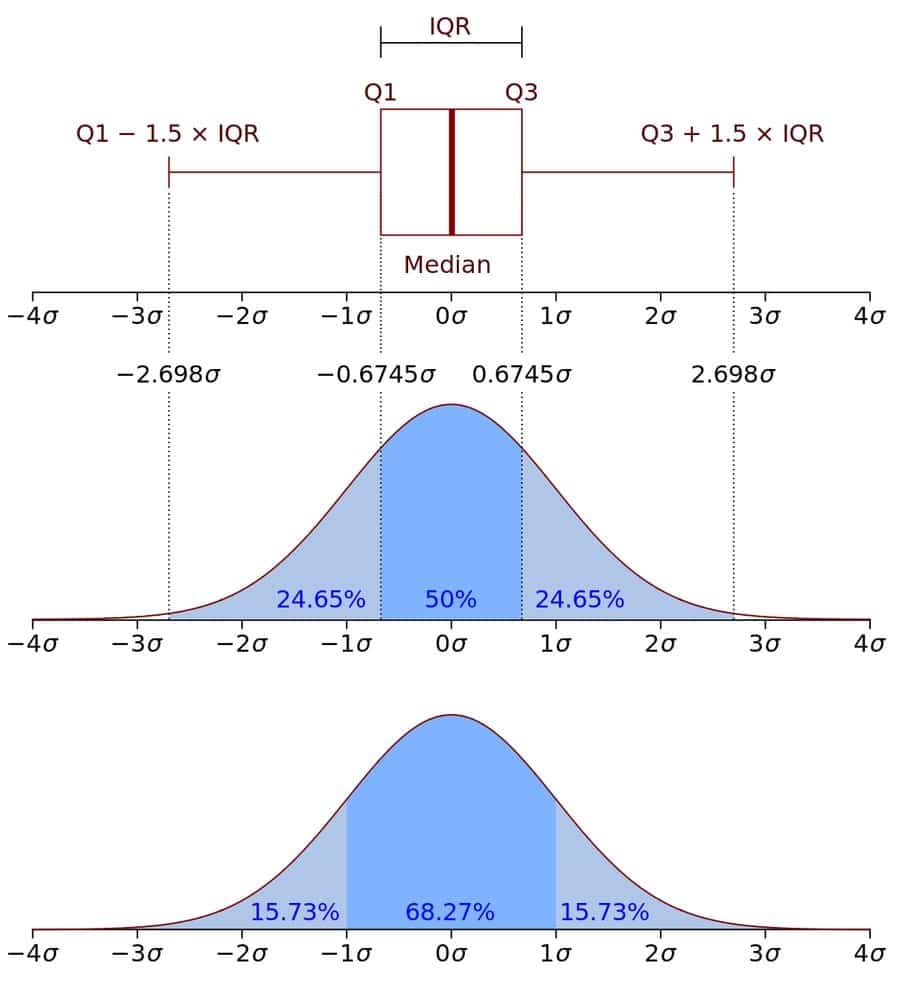
Q-63: What is IQR (Interquartile Range) and Usage?
This is a routinely asked Big Data interview question. The interquartile extend (IQR) is a proportion of inconstancy, in view of isolating an informational collection into quartiles. Quartiles partition a position requested informational index into four equivalent parts. The characteristics that segment each part are known as the principle, second, and third quartiles, and they are shown by Q1, Q2, and Q3, independently.
Q1 is the “center” esteem in the principal half of the rank-requested informational collection. Q2 is the middle of an incentive in the set. Q3 is the “center” esteem in the second 50% of the rank-requested informational index. The interquartile run is equivalent to Q3 less Q1.
IQR helps to find outliers. IQR gives a thought of how well they mean, for instance, speaks to the information. If the IQR is large, the mean is not as a representative of the data. This is on the grounds that an enormous IQR shows that there are likely huge contrasts between singular scores. If each sample data set within a larger data set have a similar IQR, the data is considered to be consistent.
The diagram below shows a simple analysis of IQR and the spread of data with standard deviation.
Q-64: Explain what is Map Reduce?
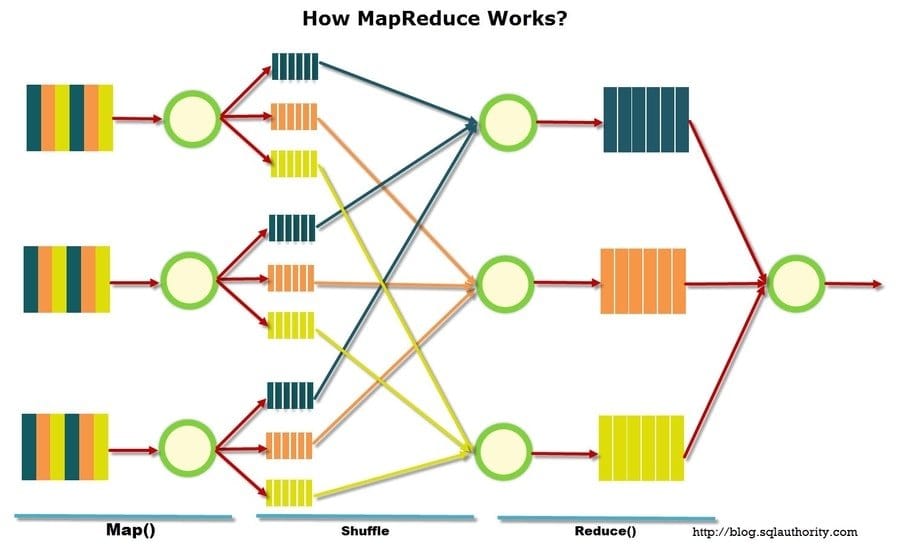
This is a Data Analytics interview question that asks for the purpose of Map Reduce. Map Reduce is a system utilizing which applications are composed to process colossal measures of information, in parallel, on huge bunches of ware equipment in a dependable way. Map Reduce is based on Java. Map Reduce contains two significant errands, Map and Reduce.
The map takes a great deal of data and changes over it into another game plan of data, where solitary segments are isolated into key-regard sets. Furthermore, diminish task, which takes the yield from a guide as a piece of information and consolidates those key-esteem sets into a littler arrangement of key-esteem sets.
Q-65: What does “Data Cleansing” mean? What are the best ways to practice this?
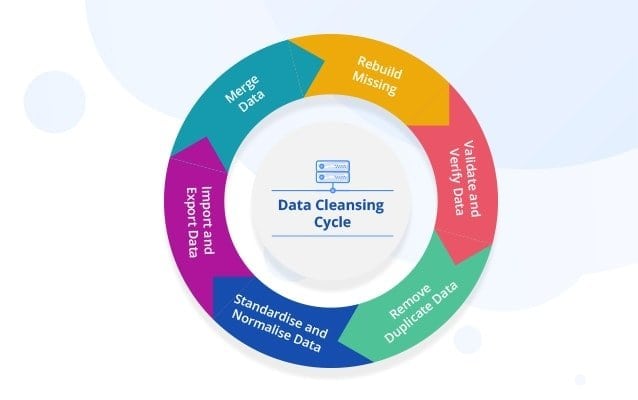
This is a significant Data Analytics interview question. Data cleansing is the way toward modifying information in a given stockpiling asset to ensure that it is precise and right.
Here a suitable practice is outlined. The first step is to monitor errors. Trends of error can be observed to simplify work. The second step is to validate accuracy. The accuracy of the data has to be validated once the existing database is cleaned. Data tools that allow cleaning data in real-time can be used, which implements machine learning.
The third step is to analyze. Reliable third-party sources can capture information directly from first-party sites. At that point, the information is cleaned and assembled to give increasingly finish data to business knowledge and investigation. The fourth step is to communicate the final result with the team and to refine the process further.
Q-66: Define “Time Series Analysis”
This is a frequently asked Data Science question. Time series investigation is a measurable strategy that manages pattern examination. A lot of perceptions are made on the qualities that a variable takes on various occasions. The following shows the weather pattern.
Q-67: Can you cite some examples where both false positive and false negatives are equally important?
For a cat allergy test, the test shows positive for 80% of the total number of people who have an allergy, and 10% of the total number of people who do not have an allergy.

Another example is the ability to distinguish colors, which is important for a video editing app.

Q-68: Can you explain the difference between a Test Set and a Validation Set?
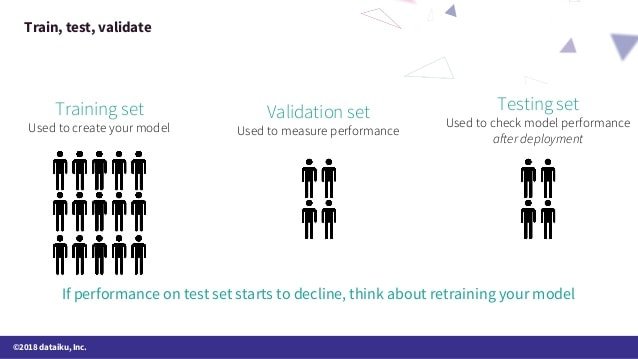
This is a Data Science interview question that asks to explain between the two. A validation set is utilized to tune the hyperparameters (e.g., neural system models, the piece works in SVMs, the profundity of an irregular woodland tree). There is a hazard to overfit to the approval set when attempting to upgrade hyperparameters too completely. A test set is utilized to survey the presentation (i.e., speculation and prescient power). The test data set may not be used in the model building process.
Q-69: How will you assess the statistical significance of insight, whether it is a real insight or just by chance?
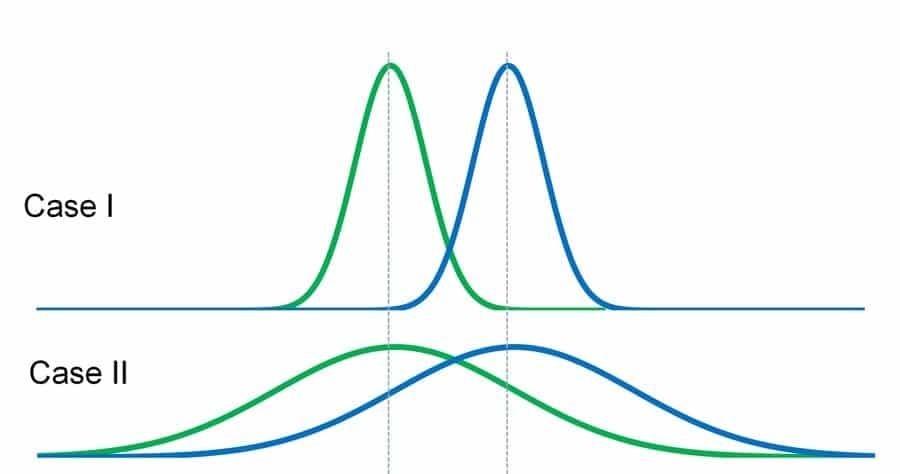
Another notice in data science interview questions is, “In what capacity will you survey the measurable importance of understanding whether it is a genuine knowledge or just by some coincidence”? This question was also seen to have come in a Statistics interview question.
An invalid theory is first expressed. A suitable statistical test is chosen, such as z- test, t-test, etc. A critical region is chosen for the statistics to lie in that is extreme enough for the null hypothesis to be rejected, called a p-value. Observed test statistics data is calculated checked whether it lies in the critical region.
Q-70: What are the important skills to have in Python concerning data analysis?

You would also get a Data Analytics interview question like this in your interview! The answer may go like, data scrapping is a required skill. Online data is collected using Python packages like urllib2. SQL is another skill – unstructured data is turned into structured data, and relations between variables are established.
Data frames – machine learning has to be enabled in the SQL server, or MapReduce is implemented before data can be processed using Pandas. Data visualization, the process of drawing charts, can be done using matplotlib.
Q-71: What is sampling? Types of sampling techniques?
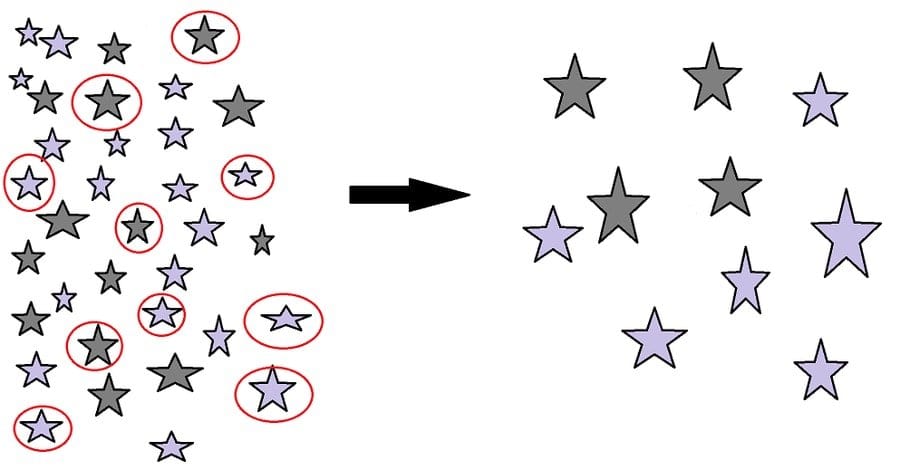
This is an essential Data Analytics interview question. Sampling, also known as testing is a procedure utilized in the factual investigation in which a foreordained number of perceptions are taken from a bigger populace.
In irregular inspecting, every component in the populace has an equivalent possibility of happening. In methodical testing, the once-over of segments is “made a note of,” for instance, each kth part is taken. Inconvenience sampling, the first few elements of an entire dataset, are taken into account.
Cluster testing is practiced by partitioning the populace into groups – normally topographically. The groups are haphazardly chosen, and every component in the chose bunches are utilized. Stratified examining additionally separates the populace into bunches called strata. Nonetheless, this time, it is by some trademark, not topographically. An example is taken from every one of these strata utilizing either irregular, orderly, or accommodation inspecting.
In the diagram below, there are a large number of stars in a bag, out of which random sampling is done to collect 10 stars(marked red), which may be used to calculate the probability of lavender star coming out of the bag, which value is applicable to the whole population of stars.
Q-72: Python or R – Which one would you prefer for text analytics?
This is an every now and again asked the Data Scientist interview question. Python would be superior to R since it has a Pandas library that gives simple utilization of information structures and elite information examination devices. R is more appropriate for AI than just content examination. Python performs quicker than R.
Q-73: How can you generate a random number between 1 – 7 with only a die?
This is a common Data Scientist interview question, where the solution can be found in numerous methods. One way is to roll the same die twice, and then assign the following values to the numbers.
After the die is thrown two times, if upon second throw 1 appears, the number assigned is 7. Else, the number assigned is the same as the number on the first die.

Q-74: How do you find the 1st and 3rd quartile?
This question comes very frequently in statistics interview questions. Quartiles are one of the most important aspects of statistics. The first quartile, signified by Q1, is the center worth or middle of the lower half of an informational collection. In less complex words, this implies about 25% of the numbers in an informational index lie beneath Q1, and about 75% lie above Q1.
The third quartile, signified by Q3, is the middle of the upper portion of an informational collection. This implies about 75% of the numbers in the informational collection lie below Q3 and about 25% falsehood above Q3.
Q-75: What is the process of Data Analysis?
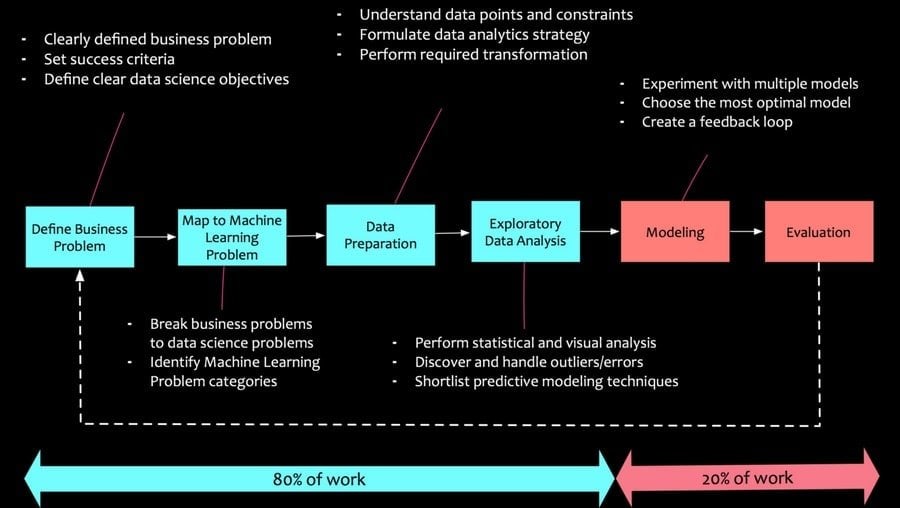
The answer to another one of the frequently asked data Scientist interview questions shall be, data analysis is used to gain business profits by gathering insights and generating reports of data. This can be done by collecting, cleansing, interpreting, transforming, and modeling those data.
To describe the processes in details, you can say,
- Collect data: This is one of the crucial steps as in this step, the data gets collected from various sources and is stored. After that, the data is cleaned and prepared; that is, all the missing values and outliers are removed.
- Analyze data: Analyzing the data is the next step after the data is ready. For further improvements, a model is run repeatedly, and a certain mode is validated, which checks whether the business requirements are met.
- Create reports: Finally, the model is implemented, and the stakeholders are passed on with the reports generated after implementation.
Q-76: Explain Gradient Descent.
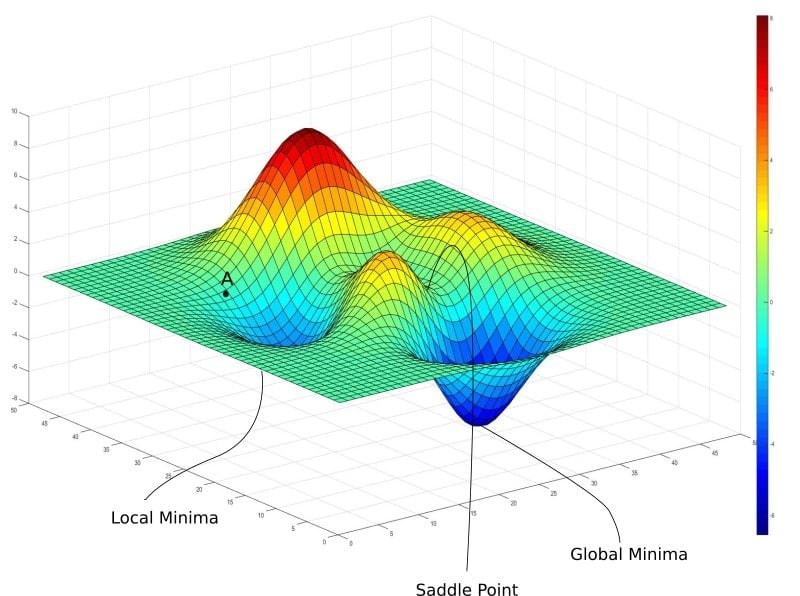
This is a very efficient data science interview question, as well as a very familiar data analytics interview question. We have to think about how the gradient descent works. Well, the cost of any coefficients evaluates when we insert them in a function and calculate the cost of the derivative. The derivative is again calculus and points the slope of a function at a given point.
The gradient is a mathematical term that is a part of math, but it has a very important role in data science and machine learning. This is a kind of algorithm that is used to minimize a function. It works by moving the direction of a particular slope of a figure defined by the negative of that gradient.
Q-77: What are the variants of Back Propagation?
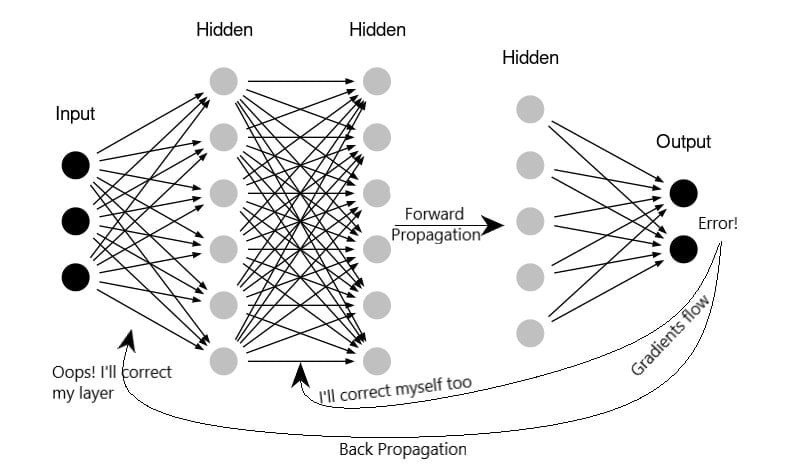
This is one of the very common data science interview questions these days. Backpropagation is basically a very common and efficient method or algorithm that makes sure the accuracy of prediction in data mining which works in the vast field of neural networking. This is a propagation way that determines and minimizes the loss that every node is responsible for by computing the gradients at the output layer.
There are three primary varieties of back-propagation: stochastic (likewise called on the web), batch, and mini-batch.
Q-78: Explain what is n-gram?
You would also get data analytics and statistics interview questions like this in your interviews! The answer may go like, for a given sequence of text or speech, a continuous sequence of n items is known as an n-gram. In the form of (n-1), the n-gram predicts the next item in such a sequence, and therefore, it can be called a probabilistic language model.
Q-79: What is exploding gradients?
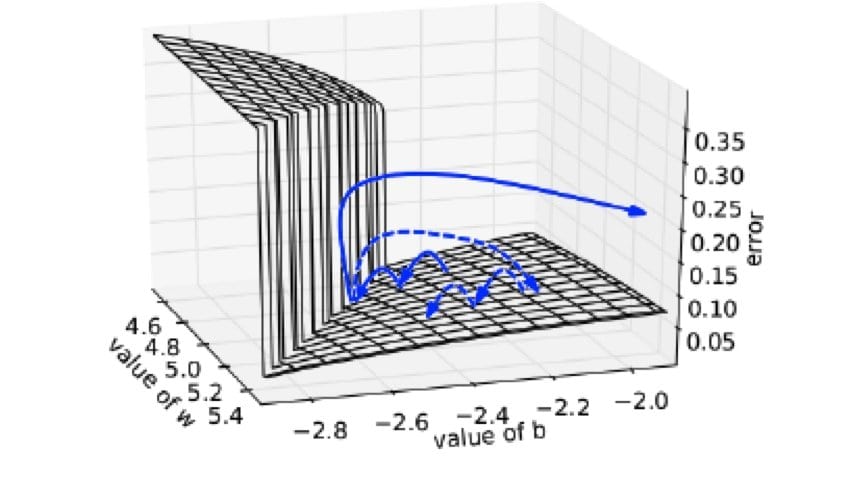
The exploding gradient is a very important data science interview question, as well as a big data interview question. Now, the exploding gradient is an error gradient or difficulty of neural network that generally happens during the training when we use gradient descent by backpropagation.
This problem can occur in an unstable network. An unstable network sometimes lacks behind learning from training data, and sometimes it also cannot trace large inputs. That means it cannot complete the learning. It makes the value so large that it overflows, and that result is called NaN values.
Q-80: Explain what is correlogram analysis?
Analysis-based data science interview questions such as this particular one can also appear in your data science interview. The response would be that the geo-spatial analysis in geography is known as a correlogram analysis, and it the most communal form of it. Separation based information additionally utilizes it, when the crude information is communicated as a separation rather than singular point esteems.
Q-81: What are the different kernel’s functions in SVM?
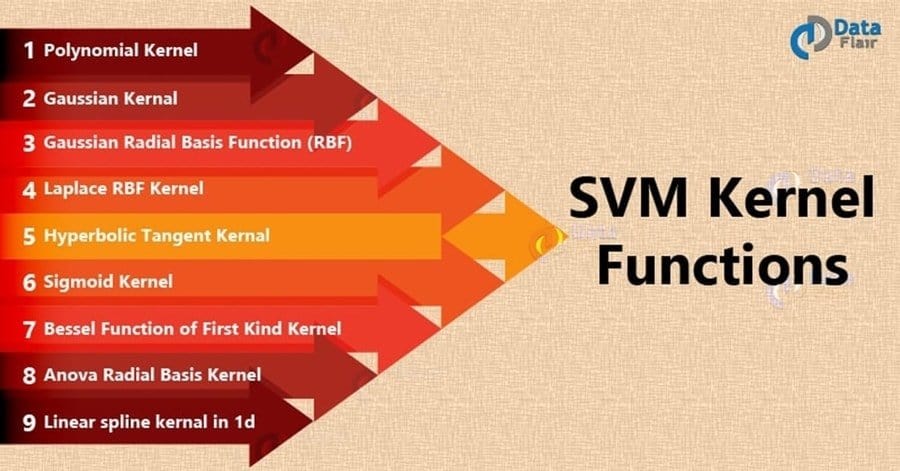
This is one of the most common questions asked in a data science interview. You can find this question commonly in all the lists of data science interview questions as well as statistics interview questions. The candidate should answer this question very specifically. There are four types of kernels in SVM:
- Linear Kernel
- Polynomial kernel
- Radial basis kernel
- Sigmoid kernel
Q-82: What is bias, variance trade-off?
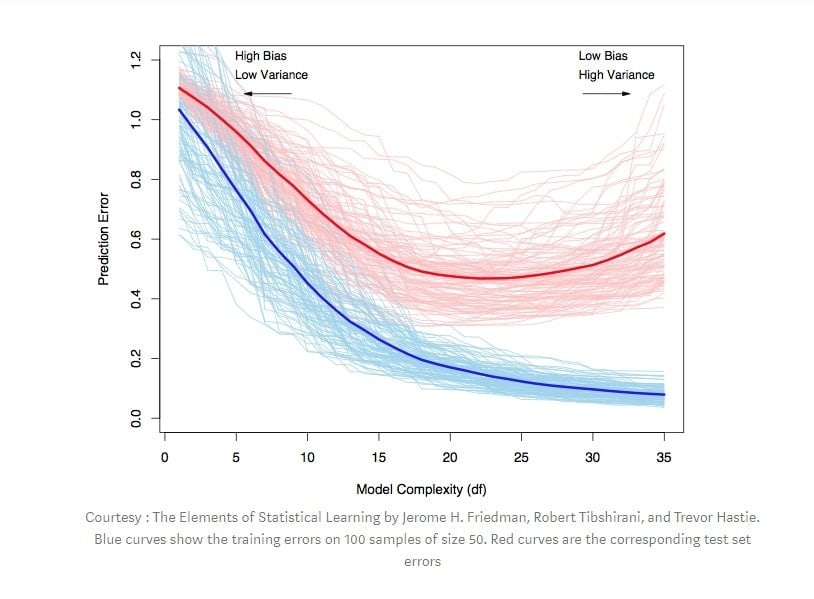
This is a fundamental Statistics interview question. The bias-variance trade-off is an estimator of error. The bias-variance trade-off has a high value if bias is high and variance is low, or if a variance is high and bias is low.
Q-83: What is Ensemble Learning?
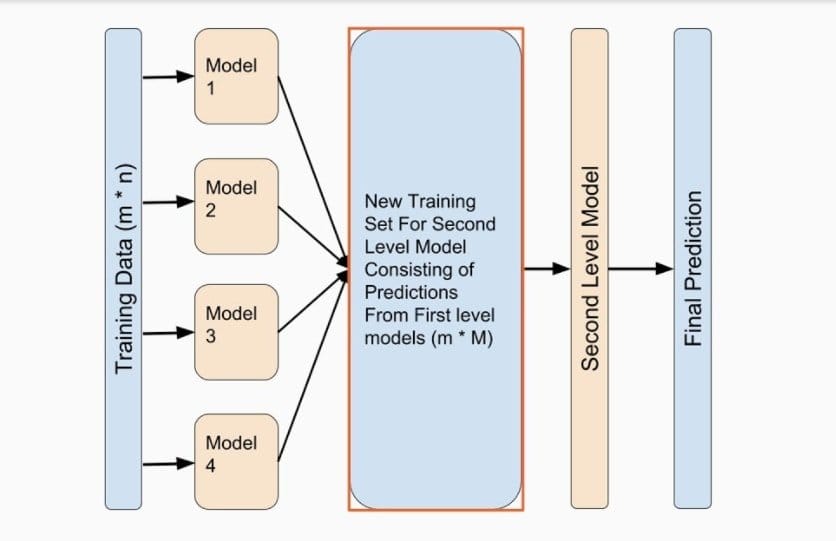
This is much of the time asked Big Data interview question. Ensemble learning is an AI strategy that joins a few base models to deliver one ideal prescient model.
Q-84: What is the role of the Activation Function?
Another widespread data science and data analyst interview question is the activation function and its role. In short, the activation function is such a function that makes sure the output’s non-linearity. It decides if the neuron ought to be initiated or not.
The activation function plays a very significant role in artificial neural networking. It works by computing the weighted sum and, if needed, further adds bias with it. The fundamental job of the enactment work is to guarantee the non-linearity in the yield of a neuron. This function is responsible for weight transforming.
Q-85: What is ‘Naive’ in a Naive Bayes?
An absolute necessity asks the data science interview question as well as just as data analyst interview question is Naïve Bayes. information science talk with inquiry
Before the word ‘Naïve,’ we should understand the concept of Naïve Bayes.
Naïve Bayes is nothing but the assumption of features for any class to determine whether those particular features represent that class or not. This is something like comparing some criteria for any class to make sure if this refers to that class or not.
The Naïve Bayes is ‘Naïve’ as it is the independence of the features from each other. And this means ‘almost’ but not true. It tells us that all features are different or independent from each other, so we don’t need to confide in the duplicates while making the classification.
Q-86: What is TF/IDF vectorization?
This Data Science interview question relates to converting unstructured data to structured data, using TF/IDF vectorization. TF-IDF is a condensing for Term Frequency-Inverse Document Frequency and is a typical calculation to change content into an important portrayal of numbers. The system is broadly used to remove includes crosswise over different NLP applications.
The following is an example.
Q-87: Explain what regularization is and why it is useful.
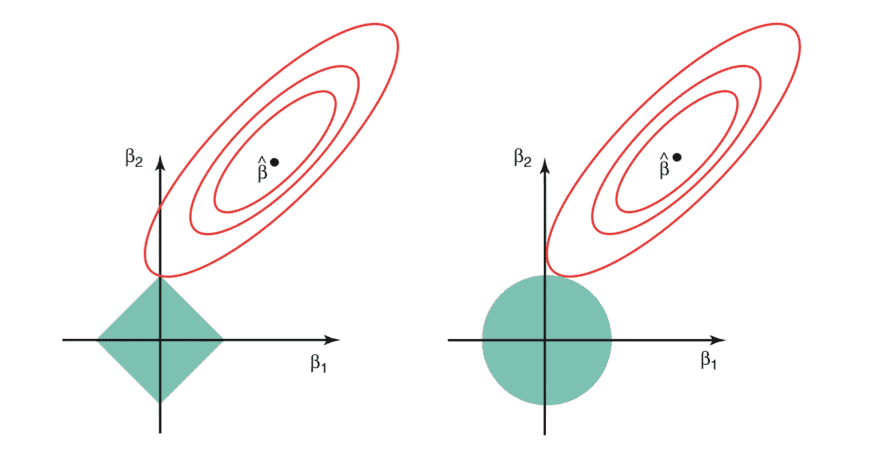
You can also come across a different question in your Data science interview, such as “What are regularization and its usefulness.” You can say that regularization is nothing but a technique or concept which prevents the overfitting problem in machine learning. This is a very useful technique for machine learning in terms of solving the problem.
As there are two models for generalization of data. One is a simple model, and then another one is a complex model. Now a simple model is a very poor generalization model, and on the other hand, a complex model cannot perform well due to overfitting.
We need to figure out the perfect model for dealing with machine learning, and regularization exactly does that. It is nothing but adding plenty of terms to the objective function to control the model complexity using those plenty terms.
Q-88: What are Recommender Systems?
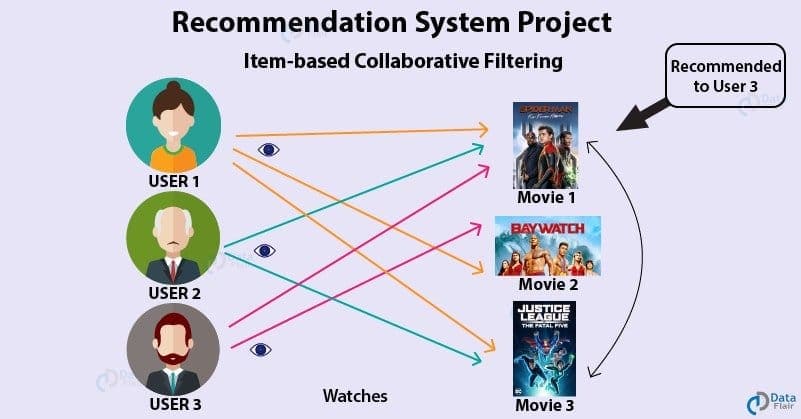
As a recommended system is one of the most popular applications these days, so this is a very important data science interview question. We people are expecting the advantages of the Recommender Systems regularly. These are basically used to predict for an item’s “rating” or “preferences.”
It helps people to get reviews or recommendations and suggestions from the previous users. There are 3 unique sorts of Recommender System. They are- Simple Recommenders, Content-based Recommender, Collaborative filtering engines.
The world’s most popular tech-based companies are already using these for various purposes. YouTube, Amazon, Facebook, Netflix, and such most famous applications are also applying them in various forms.
Q-89: Explain what is KPI, design of experiments, and 80/20 rule?
This could be the next important question in your data science interview. It is also sometimes seen to come in big data interviews, so prepare for it accordingly.
The KPI represents the Key Performance Indicator. It is a metric about the business process, and it consists of all combinations of spreadsheets, reports, and charts of it.
Design of experiments: It is the underlying procedure that is utilized to part your information, test, and set up information for measurable examination.
80/20 standards: It implies that 80 percent of your pay originates from 20 percent of your customers.
Q-90: What is an Auto-Encoder?
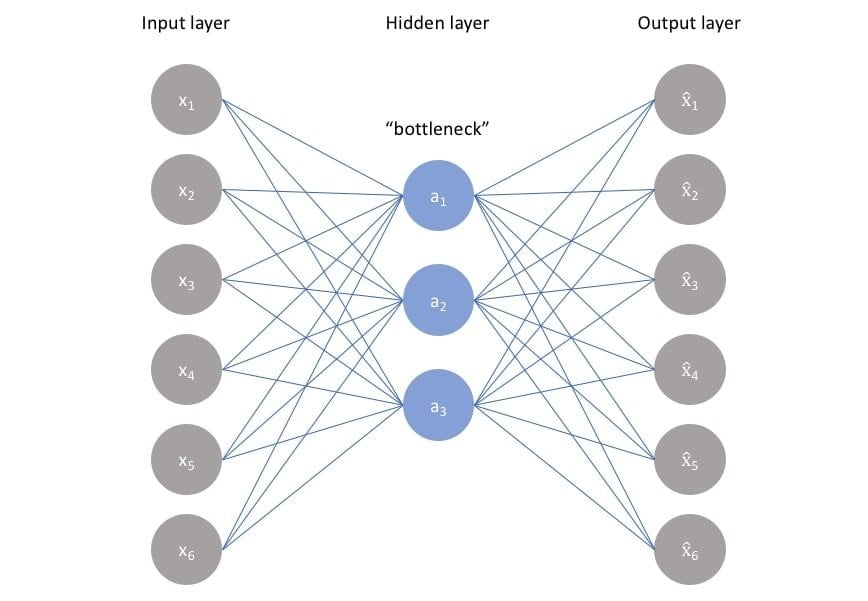
Another very familiar data science interview question topic is Auto-Encoder. Auto-Encoder is such a machine learning algorithm that is unsupervised in nature. Auto-Encoder also uses backpropagation, and its main context is to set a target value that would be equal to the input.
Auto-Encoder reduces data by ignoring the noise in data and also learn to reconstruct data from the reduced form. It compresses and encodes data very efficiently. The mechanism of it is trained to attempt to copy data from its output.
Anyone can make the best use of Auto-Encoder if they have correlated input data, and the reason behind this is the operation of Auto-Encoder relies upon the correlated nature to compress data.
Q-91: What is the basic responsibility of a Data Scientist?

One of the most important questions for any data science interview question asks about the basic role or responsibility of a data scientist. But before that, a data scientist has to have a very clear basement in computer science, analytics, statistical analysis, basic business sense, etc.
A data scientist is someone who is occupied under an institution or company for making machine learning-based objects and also solves complex virtual and real-life problems. His role is to update the machine learning system with time and figure out the most efficient way of handling and dealing with any kind of programming as well as machine-related problem.
Q-92: Explain what are the tools used in Big Data?
Big data interview or a data science coming up? Do not worry because this basic data science interview question will cover both those interviews. The apparatuses utilized in Big Data incorporate Hadoop, Hive, Pig, Flume, Mahout, Sqoop.
Q-93: What is a Boltzmann Machine?
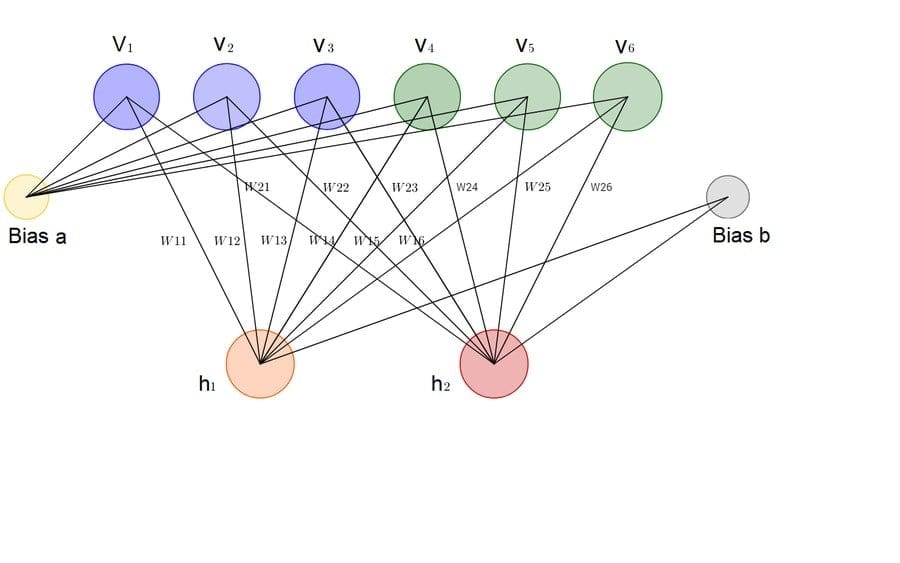
The Boltzmann machine is a very basic data science interview question, but an important big data question as well. Shortly we can say a Boltzmann machine is stochastic of neural network. In other words, we can also call it the generative counterpart of the Hopfield network.
The Boltzmann machine is known as one of the first neural networks that are capable enough to learn the internal representation and able to solve critical combinational problems. The Boltzmann machine has its very own significant characteristic to work as an algorithm. It is said that if the connectivity of the Boltzmann machine is properly constrained, then it can be efficient enough to be useful for practical problems.
Q-94: What is the KNN imputation method? Can KNN be used for categorical variables?
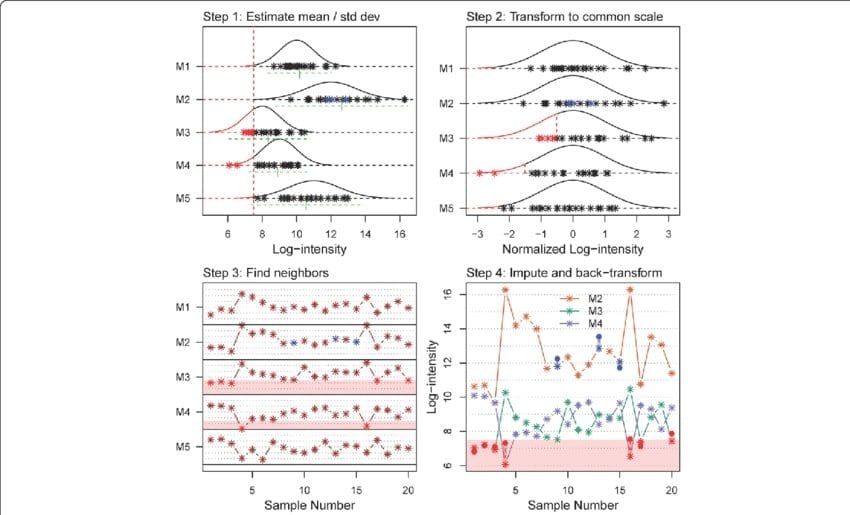
This entry of data science and data analytics interview questions is probably one of the basic ones but are never missed by interviewers. KNN is a helpful calculation and is generally used to coordinate focuses with its nearest k neighbors in a multi-dimensional space. KNN can be utilized for managing a wide range of missing information as it can work with information that is persistent, discrete, ordinal, and straight out.
The answer to the second part of this data science interview question is a yes, that KNN can be used for categorical values. It can be done by converting the categorical values into numbers.
Q-95: What are the types of Splunk Licenses?
This next entry of data science interview questions is a must-read as its chances of coming are very high. The following mentions the different types of Splunk Licenses: Beta license, Licenses for cluster members which are used for index duplication, Free license, Enterprise license, Forwarder license, Licenses for search heads that are used for dispersed search
Q-96: What happens if the License Master is unreachable?
This is a must-read big data interview question, because not only will it help you to prepare for your big data interview, but it will also help you with your data science interview as well!
A very interesting way to answer this question is that if the license master is not available, the job is partially handled to the license slave, which starts a 24-hour timer. This timer will cause the search to be blocked on the license slave after the timer ends. The drawback to this is that users will not be able to search for data in that slave until the license master is reached again.
Q-97: Explain Stats vs Transaction commands.
Another latest Data Scientist interview question is on the two very important commands – Stats and Transaction. To answer this data science interview question, we first have to give the uses of each command. In two specific cases is the transaction command most needed:
First, during two transactions, when it is very important to have them discriminated from each other, but sometimes the unique ID is not sufficient. This case is usually seen during web sessions that are identified by a cookie/client IP due to the identifier being reused. Second, when an identifier is reused in a field, there is a specific message which marks the beginning or end of a transaction.
In different cases, it is normally better to work with the direction of the details. For example, in a distributed search environment, it is highly recommended to use stats as its performance of the stats command is much higher. Also, if there is a unique ID, the stats command can be used.
Q-98: What is the definition of Hive? What is the present version of Hive? Explain ACID transactions in Hive.
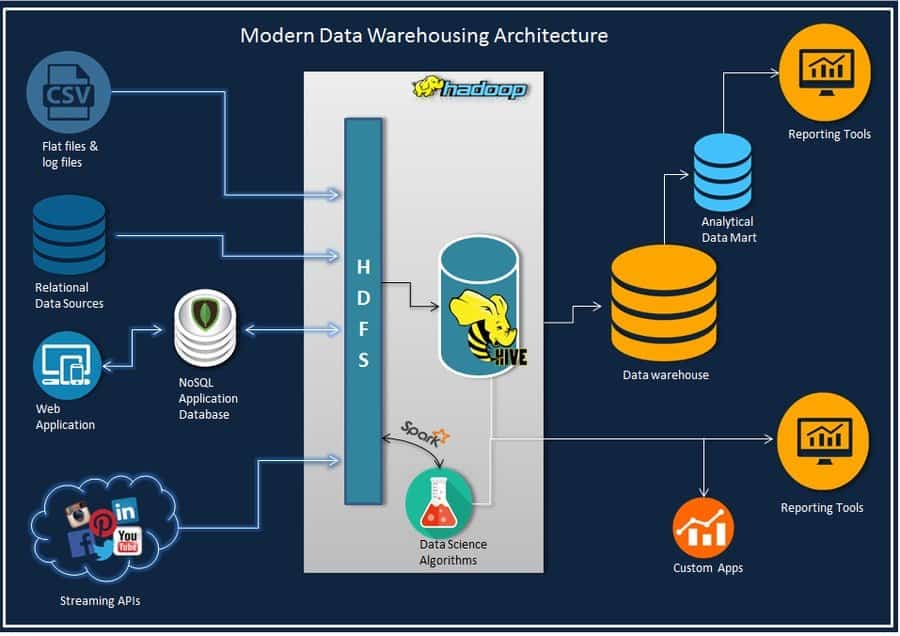
To define this data science interview question in the shortest possible manner, we can say that hive is just an open-source data warehouse system used for the querying and analyzing of large datasets. It is fundamentally the same as SQL. The present adaptation of the hive is 0.13.1.
Probably the best thing about the hive is that it underpins ACID (Atomicity, Consistency, Isolation, and Durability) exchanges. The ACID exchanges are given at push levels. Following are the options Hive uses to support ACID transactions:
- Insert
- Delete
- Update
Q-99: Explain what is Hierarchical Clustering Algorithm?
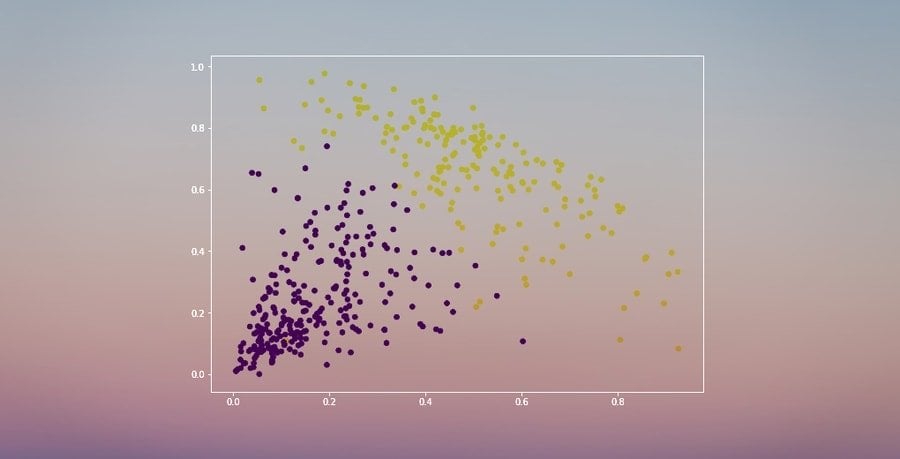
Now, we all give interviews, but only some of us ace it! This data science yet data analytics interview question is all you have to pro that data science interview. So answer it wisely.
There are groups in every situation, and what hierarchical clustering algorithm does is combine those groups and sometimes also divide among them. This makes a progressive structure that grandstands the request wherein the gatherings are partitioned or consolidated.
Q-100: Explain what is K-mean Algorithm?
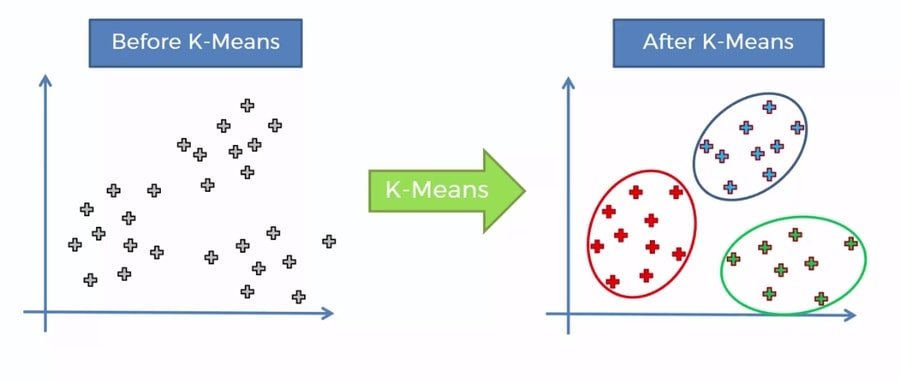
Questions on algorithms are very important for your data science interviews as well as big data and data analytics interviews. K-means is an unsupervised learning algorithm, and its job is to partition or cluster. It doesn’t require any named focuses. A set of unlabeled points and a threshold is the only requirement for K-means clustering. Due to this lack of unlabeled points, k – means clustering is an unsupervised algorithm.
Ending Thoughts
Data science is a vast topic, and also it is incorporated with many other areas like machine learning, artificial intelligence, big data, data analyst, and so forth. Therefore, any tricky and complicated Data science interview questions can be asked to examine your knowledge of data science.
Showing the interviewer that you are very passionate about what you do is an important aspect of your interview, and this can be shown by portraying an enthusiastic response. This will also indicate that you have a strategic outlook for your technical expertise to help business models. Therefore, you have always to keep your skill up-to-date and furnish. You have to learn and practice more and more Data science techniques scrupulously.
Please leave a comment in our comment section for further queries or problems. I hope that you liked this article and it was beneficial to you. If it was, then please share this article with your friends and family via Facebook, Twitter, Pinterest, and LinkedIn.
Related Courses
RPA (Robotic Process Automation)
Machine Learning with 9 Practical Applications
Mastering Python – Machine Learning
Data Sciences with Python Machine Learning
Data Sciences Specialization
Diploma in Big Data Analytics
Learn Internet of Things (IoT) Programming
Oracle BI – Create Analyses and Dashboards
Microsoft Power BI with Advance Excel
